# 理解 Proxy 和 Reflect
# Proxy
使用 Proxy 可以创建一个代理对象。它能够实现对其他对象(也就是非原始值)的代理,也就是说,Proxy 只能代理对象,无法代理非对象值,例如字符串、布尔值等。(故非引用值即简单数据类型作为响应式数据,都是将其转化为对象。)
代理:指的是对一个对象基本语义的代理,它允许我们拦截并重新定义对一个对象的基本操作。
基本操作:对对象属性的增删改查被称为基本语意,对基本语意的操作被称为基本操作。
非基本操作:也叫复合操作,由多个基本操作组合而成。例如执行对象上的方法,这里由两个基本操作构成:①获取对象上的这个方法;②调用执行这个方法。
对象的基本操作:单纯地读或写;对象的复合操作:如对象方法调用,既读取了对象、又调用了方法。
复合操作由基本操作组合而成,也就是说,我们可以通过将复合操作拆分成多个基本操作的方式,来间接代理复合操作。
# 基本操作
Proxy 只能够拦截对一个对象的基本操作。get 函数用来拦截读取操作,set 函数用来拦截设置操作,apply 用来拦截函数的调用。
obj.foo // 读取属性 foo 的值
obj.foo++ // 读取和设置属性 foo 的值
2
类似这种读取、设置属性值的操作,就属于基本语义的操作,即基本操作。既然是基本操作,那么它就可以使用 Proxy 拦截:
// 第一个参数是被代理的对象,第二个参数也是一个对象,这个对象是一组夹子(trap)
const p = new Proxy(obj, {
// 拦截读取属性操作
get() { /*...*/ },
// 拦截设置属性操作
set() { /*...*/ }
})
2
3
4
5
6
7
在 JavaScript 的世界里,万物皆对象。例如一个函数也是一个对象,所以调用函数也是对一个对象的基本操作:
const fn = (name) => {
console.log('我是:', name)
}
// 调用函数是对对象的基本操作
fn()
2
3
4
5
因此,我们可以用 Proxy 来拦截函数的调用操作:
const p2 = new Proxy(fn, {
// 使用 apply 拦截函数调用
apply(target, thisArg, argArray) {
target.call(thisArg, ...argArray)
}
})
p2('hcy') // 输出:'我是:hcy'
2
3
4
5
6
7
# 复合操作
其实调用对象下的方法就是一个典型的非基本操作,我们称它为复合操作:
obj.fn()
它由两个基本语义组成:get 和 apply。先通过 get 操作得到 obj.fn 属性,然后再通过 apply 调用 。
# Reflect
Reflect 是一个全局对象,其下有许多方法,任何在 Proxy 的拦截器中能够找到的方法,都能够在 Reflect 中找到同名函数。
拿Reflect.get 函数来说,它的功能就是提供了访问一个对象属性的默认行为,例如下面两个操作是等价的:
const obj = { foo: 1 }
// 直接读取
console.log(obj.foo) // 1
// 使用 Reflect.get 读取
console.log(Reflect.get(obj, 'foo')) // 1
2
3
4
5
6
实际上Reflect.get 还能接收第三个参数,即指定接收者 receiver,可以理解为函数调用过程中的 this,receiver 只有在访问的是 getter 或者 setter 时才有效,例如:
const obj = { foo: 1 }
console.log(Reflect.get(obj, 'foo', { foo: 2 })) // 输出的是 1
2
在这段代码中,我们指定第三个参数 receiver 为一个对象 { foo: 2 },但是这时读取不到 receiver 对象的 foo 属性值(读取不到 2),因为原 obj 并未指定 getter,需要把原函数的 foo 变成一个 getter 才能读取到 2(需要第二个参数是 getter 属性,否则不生效)。
Reflect 与响应式数据的实现密切相关。回顾一下之前实现响应式数据的代码:
const obj = { foo: 1 }
const p = new Proxy(obj, {
get(target, key) {
track(target, key)
// 注意,这里我们没有使用 Reflect.get 完成读取
return target[key]
},
set(target, key, newVal) {
// 这里同样没有使用 Reflect.set 完成设置
target[key] = newVal
trigger(target, key)
}
})
2
3
4
5
6
7
8
9
10
11
12
13
在 get 和 set 拦截函数中,我们都是直接使用原始对象 target 来完成对属性的读取和设置操作的,其中原始对象 target 就是上述代码中的 obj 对象。
我们借助 effect 让这段代码的问题暴露出来。首先,我们修改一下 obj 对象,为它添加 bar 属性:
const obj = {
foo: 1,
get bar() {
return this.foo // 这里的 this 指向的是谁呢?
}
}
2
3
4
5
6
可以看到,bar 属性是一个访问器属性,它返回了 this.foo 属性的值。接着,我们在 effect 副作用函数中通过代理对象 p 访问 bar 属性:
effect(() => {
console.log(p.bar) // 1
})
2
3
理论上,当 effect 注册的副作用函数执行时,会读取 p.bar 属性,它发现 p.bar 是一个访问器属性,因此执行 getter 函数。由于在 getter 函数中通过 this.foo 读取了 foo 属性值,因此我们认为副作用函数与属性 foo 之间也会建立联系。当我们修改 p.foo 的值时应该能够触发响应,使得副作用函数重新执行才对。然而实际并非如此!!
当我们尝试修改 p.foo 的值时,副作用函数并没有重新执行:
p.foo++
实际上,问题就出在 bar 属性的访问器函数 getter 里,本来 p.bar 访问到的是应该 obj.foo的值,但是实际上 obj.foo 并不会被收集依赖,因为 obj 对象没有设置 get 拦截。
我们回顾一下整个流程:
1、我们通过代理对象 p 访问 p.bar,这会触发代理对象的 get 拦截函数执行:
const p = new Proxy(obj, { get(target, key) { track(target, key) // 注意,这里我们没有使用 Reflect.get 完成读取 return target[key] }, // 省略部分代码 })1
2
3
4
5
6
7
82、在 get 拦截函数内,通过
target[key]返回属性值。其中 target 是原始对象 obj,而 key 就是字符串 'bar',所以 target[key] 相当于obj.bar。因此,当我们使用p.bar访问 bar 属性时,它的 getter 函数内的 this 指向的其实是原始对象 obj,这说明我们最终访问的其实是 obj.foo。很显然,在副作用函数内通过原始对象访问它的某个属性是不会建立响应联系的,所以出现了无法触发响应的问题。这等价于:effect(() => { // obj 是原始数据,不是代理对象,这样的访问不能够建立响应联系 obj.foo })1
2
3
4因为这样做不会建立响应联系,所以出现了无法触发响应的问题。
这时 Reflect.get 函数就派上用场了,代理对象的 get 拦截函数接收第三个参数 receiver,它代表谁在读取属性:
const p = new Proxy(obj, {
// 拦截读取操作,接收第三个参数 receiver,它代表谁在读取属性
get(target, key, receiver) {
track(target, key)
// 使用 Reflect.get 返回读取到的属性值
return Reflect.get(target, key, receiver)
},
// 省略部分代码
})
2
3
4
5
6
7
8
9
target 是被代理的原始对象 obj,key 是被读取的属性的名称,receiver 是执行操作的代理对象(这里是 p)。receiver 参数会被用作 Reflect.get 方法的 this 值,如果没有提供 receiver 参数,target 本身会被用作 this 值。
访问器属性 bar 的 getter 函数内的 this 指向代理对象 p:
const obj = {
foo: 1,
get bar() {
// 现在这里的 this 为代理对象 p,相当于隐式调用了 p.foo,从而触发了 track(p, 'foo')
return this.foo
}
}
2
3
4
5
6
7
可以看到,this 由原始对象 obj 变成了代理对象 p。很显然,这会在副作用函数与响应式数据之间建立响应联系,从而达到依赖收集的效果。如果此时再对 p.foo 进行自增操作,会发现已经能够触发副作用函数重新执行了。
解决修改代理对象属性无法触发副作用函数问题
使用 Reflect 的 receiver 属性修改代理对象 getter 里关联的 this。
Refect 对象解决的就是代理对象访问原始对象方法中的 this 时,this 仍然指向原始对象,所以 proxy 监听不到访问对象的操作,导致响应式数据无变化,Reflect 对象的 get 函数的第三个参数代表原始对象中的 this 指向代理对象,这样就可以使 proxy 监听到对原始对象的操作了。
Reflect.get —— receiver —— 建立起代理对象与副作用函数之间的联系
正是基于上述原因,后面的讲解将统一使用 Reflect.* 方法。
# JavaScript 对象及 Proxy 的工作原理
# JavaScript 对象
JavaScript 中一切皆对象。在 JavaScript 中有两种对象,其中一种叫作常规对象(ordinary object),另一种叫作异质对象(exotic object)。任何不属于常规对象的对象都是异质对象。
在 JavaScript 中,函数其实也是对象。那么如何区分一个对象是普通对象还是函数?一个对象在什么情况下作为函数调用呢?答案是,通过内部方法和内部槽来区分对象,例如函数对象会部署内部方法[[Call]],而普通对象则不会。
对象的实际语义是由对象的内部方法(internal method)指定的。
内部方法:指当我们对一个对象进行操作时,在引擎内部调用的方法,这些方法对于 JavaScript 使用者来说是不可见的。
举个例子,当我们访问对象的属性时,引擎内部会调用
[[Get]]这个内部方法来读取属性值:obj.foo1ECMAScript 规范中使用 [[xxx]] 来代表内部方法或内部槽。
举个例子,当我们访问对象的属性时:
obj.foo1包括 [[Get]] 在内,一个对象必须部署 11 个必要的内部方法。
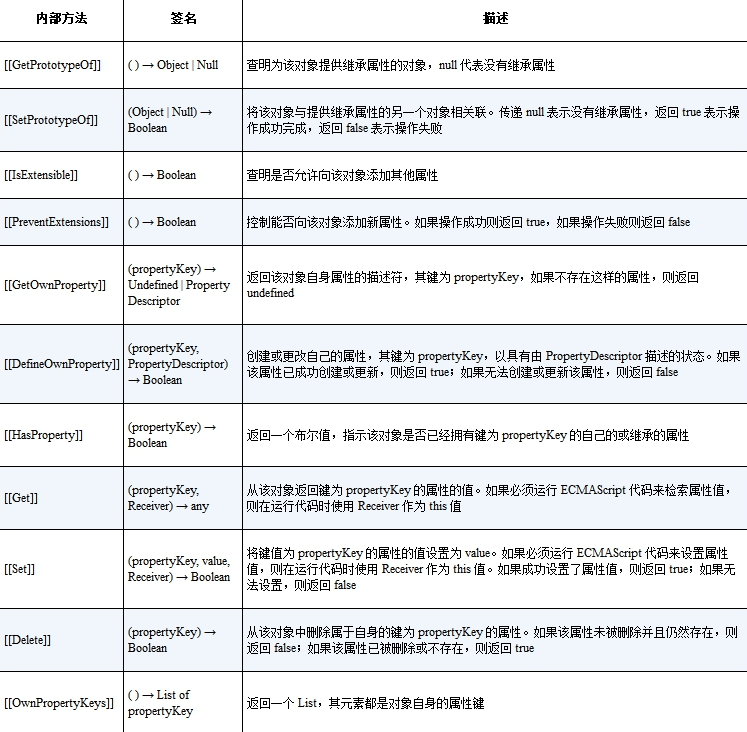
- 还有两个额外的必要内部方法:[[Call]] 和[[Construct]]。

- 如果一个对象需要作为函数调用,那么这个对象就必须部署内部方法 [[Call]]。
- 内部方法具有多态性。不同类型的对象可能部署了相同的内部方法,却具有不同的逻辑。
- 普通对象和异质对象有不同的 ECMA 规范(spec)。
内部方法具有金矿性,这是什么意思呢?这类似于面向对象里多态的概念。意思是说不同类型的对象可能部署了相同的内部方法,却具有不同的逻辑。例如普通对象和 Proxy 都部署了
[[Get]]这个内部方法,但它们的逻辑是不同的,普通对象的[[Get]]内部方法和 Proxy 对象的[[Get]]内部方法是由不同的ECMA 规范来定义的。
了解了内部方法,就可以触发什么是常规对象,什么是异质对象了。
满足以下条件的对象就是常规对象:
- 对于表1列出的内部方法,必须使用 ECMA 规范 10.1.x 节给出的定义实现;
- 对于内部方法
[[Call]],必须使用 ECMA 规范 10.2.1 节给出的定义实现; - 对于内部方法
[[Construct]],必须使用 ECMA 规范 10.2.2 节给出的定义实现。
而所有不符合这三点要求的对象都是异质对象。
# Proxy 对象
proxy 对象跟普通对象正常情况下没有什么区别,proxy 如果没有自定义代理对象本身的内部方法,则代理对象的内部方法会调用原始对象的内部方法,所以响应式数据一定要重写代理对象的内部方法和行为。
当我们通过代理对象访问属性值时:
const p = new Proxy(obj, {/* ... */})
p.foo
2
实际上,引擎会调用部署在对象 p 上的内部方法 [[Get]]。到这一步,其实代理对象和普通对象没有太大区别。它们的区别在于对于内部方法 [[Get]] 的实现,这里就体现了内部方法的多态性,即不同的对象部署相同的内部方法,但它们的行为可能不同。
具体的不同体现在,如果在创建代理对象时没有指定对应的拦截函数,例如没有指定 get() 拦截函数,那么当我们通过代理对象访问属性值时,代理对象的内部方法 [[Get]] 会调用原始对象的内部方法 [[Get]] 来获取属性值,这其实就是代理透明性质。
创建代理对象时指定的拦截函数,实际上是用来自定义代理对象本身的内部方法和行为的,而不是用来指定被代理对象的内部方法和行为的。
- Proxy 对象部署的所有内部方法如下,其中 [[Call]] 和 [[Construct]] 这两个内部方法只有当被代理的对象是函数和构造函数时才会部署。
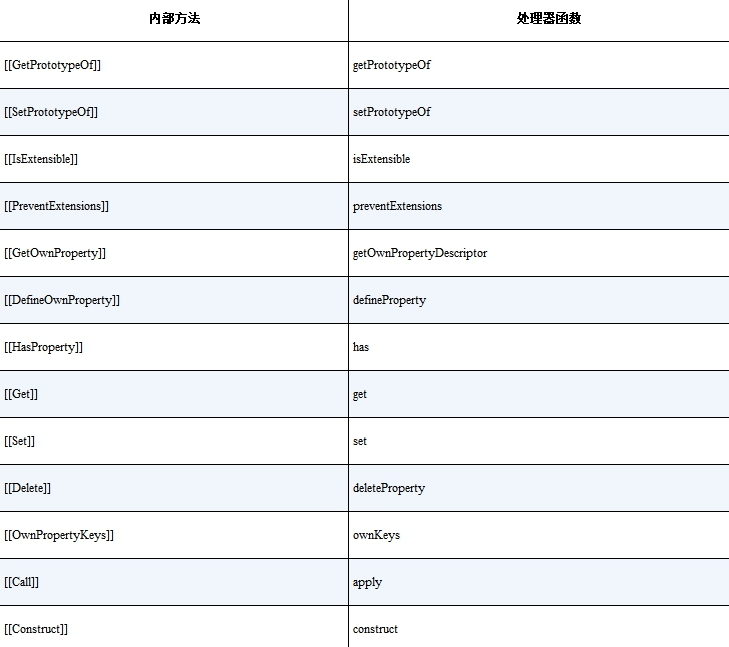
普通对象具有的内部方法,在 proxy 对象内部都有对应的同名内部方法,这使得对普通对象的所有操作都能在 proxy 对象上进行,同时 proxy 还把这些内部方法的执行逻辑通过处理器函数暴露出来给用户编写。
当我们要拦截删除属性操作时,可以使用 deleteProperty 拦截函数实现:
const obj = { foo: 1 }
const p = new Proxy(obj, {
deleteProperty(target, key) {
return Reflect.deleteProperty(target, key)
}
})
console.log(p.foo) // 1
delete p.foo
console.log(p.foo) // 未定义
2
3
4
5
6
7
8
9
10
这里 deleteProperty 实现的是代理对象 p 的内部方法和行为,为了删除被代理对象上的属性值,我们需要使用 Reflect.deleteProperty(target, key) 来完成。
这就是为什么 Vue2 的 Object.deleteProperty 不能处理对象 Delete 行为,需要用 $delete。Vue3 的 proxy 内有 deleteProperty 属性提供了这个能力。
# 如何代理 Object
# 读取
响应系统应该拦截一切读取操作,以便当数据变化时能够正确地触发响应。
1、对一个普通对象的所有可能的读取操作如下:
- 访问属性:obj.foo。
- 判断对象或原型上是否存在给定的 key:key in obj。
- 使用 for...in 循环遍历对象:for (const key in obj){}。
2、如何拦截这些读取操作?
# 访问属性
① 首先是对于属性的读取,例如obj.foo,我们知道这可以通过 get 拦截函数实现:
const obj = { foo: 1 }
const p = new Proxy(obj, {
get(target, key, receiver) {
// 建立联系
track(target, key)
// 返回属性值
return Reflect.get(target, key, receiver)
},
})
2
3
4
5
6
7
8
9
10
# 判断对象或原型上是否存在给定的 key
② in 操作符的运算结果是通过调用一个叫作 HasProperty 的抽象方法得到的。HasProperty 抽象方法的返回值是通过调用对象的内部方法 [[HasProperty]] 得到的,而 [[HasProperty]] 对应的拦截函数名叫 has,因此我们可以通过 has 拦截函数实现对 in 操作符的代理:
const obj = { foo: 1 }
const p = new Proxy(obj, {
has(target, key) {
track(target, key)
return Reflect.has(target, key)
}
})
2
3
4
5
6
7
这样,当我们在副作用函数中通过 in 操作符操作响应式数据时,就能够建立依赖关系:
effect(() => { 'foo' in p // 将会建立依赖关系 })1
2
3
# 使用 for...in 循环遍历对象
③ 任何操作其实都是由一个对象的所有基本语义方法及其组合实现的,for...in 循环也不例外。其关键点在于使用 Reflect.ownKeys(obj) 来获取只属于对象自身拥有的键,因此我们可以使用 ownKeys 拦截函数来拦截 Reflect.ownKeys 操作:
const obj = { foo: 1 }
const ITERATE_KEY = Symbol()
const p = new Proxy(obj, {
ownKeys(target) {
// 将副作用函数与 ITERATE_KEY 关联
track(target, ITERATE_KEY)
return Reflect.ownKeys(target)
}
})
2
3
4
5
6
7
8
9
10
OwnKeys 方法拦截对象的 for in 操作,不是每遍历一个属性就进入一次 ownkeys 方法,而是在 for in 操作之前执行 ownkeys 方法,track 将 for in 遍历操作所在的 effect 回调收集进 target 目标对象的 ITERATE_KEY 属性依赖集合中。
将 ITERATE_KEY 作为追踪的 key,因为 ownKeys 拦截函数与 get/set 拦截函数不同,在 set/get 中,我们可以得到具体操作的 key,但是在 ownKeys 中,我们只能拿到目标对象 target。
在读写属性值时,总是能够明确地知道当前正在操作哪一个属性,所以只需要在该属性与副作用函数之间建立联系即可。而 ownKeys 用来获取一个对象的所有属于自己的键值,这个操作明显不与任何具体的键进行绑定,因此我们只能够构造唯一的 key 作为标识,即 ITERATE_KEY。
既然追踪的是 ITERATE_KEY,那么相应地,在触发响应的时候也应该触发它才行:
trigger(target, ITERATE_KEY)1
但是在什么情况下,对数据的操作需要触发与 ITERATE_KEY 相关联的副作用函数重新执行呢?为了搞清楚这个问题,我们用一段代码来说明。假设副作用函数内有一段 for...in 循环:
const obj = { foo: 1 }
const p = new Proxy(obj, {/* ... */})
effect(() => {
// for...in 循环
for (const key in p) {
console.log(key) // foo
}
})
2
3
4
5
6
7
8
9
副作用函数执行后,会与 ITERATE_KEY 之间建立响应联系,接下来我们尝试为对象 p 添加新的属性 bar:
p.bar = 21
理论上,新增字段时,也要执行和 for---in 相关的副作用函数。当为对象添加新属性时,会对 for...in 循环产生影响,所以需要触发与 ITERATE_KEY 相关联的副作用函数重新执行。但目前的实现还做不到这一点。当我们为对象 p 添加新的属性 bar 时,并没有触发副作用函数重新执行,这是为什么呢?我们来看一下现在的 set 拦截函数的实现:
const p = new Proxy(obj, {
// 拦截设置操作
set(target, key, newVal, receiver) {
// 设置属性值
const res = Reflect.set(target, key, newVal, receiver)
// 把副作用函数从桶里取出并执行
trigger(target, key)
return res
},
// 省略其他拦截函数
})
2
3
4
5
6
7
8
9
10
11
12
当为对象 p 添加新的 bar 属性时,会触发
set()拦截函数执行,此时接收到的 key 是 bar,因此trigger()函数只会触发与 bar 相关联的副作用函数重新执行。但 for...in 循环是在副作用函数与 ITERATE_KEY 之间建立联系,这和 bar 无关,因此当我们执行 p.bar = 2 操作时,并不能正确触发响应。解析:对 p 新增属性触发了 set,也就调用了 trigger,但没有触发副作用函数执行,因为副作用函数在收集依赖时,是根据 p 内部的属性进行的依赖收集,那个时候只有一个 foo 对应的是 ITERATE_KEY,所以这里设置属性对于 p 来说,根本就不知道 bar 是啥,也就不会触发副作用函数。理论上,对 p 新增了属性,这个时候是应该触发副作用函数重新执行的。
解决办法:在执行 trigger 方法的时候,也将 ITERATE_KEY 对应的副作用函数取出来并执行。
之前是 ITERATE_KEY 和副作用函数之间建立联系,给对象加入新的之后,新的值没有和副作用函数建立联系,所以不会执行。
弄清楚了问题在哪里,解决方案也就随之而来了。当添加属性时,我们将那些与 ITERATE_KEY 相关联的副作用函数也取出来执行就可以了:
function trigger(target, key) {
const depsMap = bucket.get(target)
if (!depsMap) return
// 取得与 key 相关联的副作用函数
const effects = depsMap.get(key)
// 取得与 ITERATE_KEY 相关联的副作用函数
const iterateEffects = depsMap.get(ITERATE_KEY)
const effectsToRun = new Set()
// 将与 key 相关联的副作用函数添加到 effectsToRun
effects && effects.forEach(effectFn => {
if (effectFn !== activeEffect) {
effectsToRun.add(effectFn)
}
})
// 将与 ITERATE_KEY 相关联的副作用函数也添加到 effectsToRun
iterateEffects && iterateEffects.forEach(effectFn => {
if (effectFn !== activeEffect) {
effectsToRun.add(effectFn)
}
})
effectsToRun.forEach(effectFn => {
if (effectFn.options.scheduler) {
effectFn.options.scheduler(effectFn)
} else {
effectFn()
}
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
当 trigger 函数执行时,除了把那些直接与具体操作的 key 相关联的副作用函数取出来执行外,还要把那些与 ITERATE_KEY 相关联的副作用函数取出来执行。
# 修改
但如果仅仅修改已有属性的值,而不是添加新属性,那么问题就来了。当我们修改 p.foo 的值时:
p.foo = 2
与添加新属性不同,修改属性不会对 for...in 循环产生影响。因为无论怎么修改一个属性的值,对于 for...in 循环来说都只会循环一次,修改属性值并不会修改Object.keys(obj).length 数组的长度。此时,我们不需要触发副作用函数重新执行,否则会造成不必要的性能开销。
然而无论是添加新属性,还是修改已有的属性值,其基本语义都是 [[Set]],我们都是通过 set 拦截函数来实现拦截的,如以下代码所示:
const p = new Proxy(obj, {
// 拦截设置操作
set(target, key, newVal, receiver) {
// 设置属性值
const res = Reflect.set(target, key, newVal, receiver)
// 把副作用函数从桶里取出并执行
trigger(target, key)
return res
},
// 省略其他拦截函数
})
2
3
4
5
6
7
8
9
10
11
12
所以要想解决上述问题,当设置属性操作发生时,就需要我们在 set 拦截函数内能够区分操作的类型,到底是添加新属性还是设置已有属性:
const p = new Proxy(obj, {
// 拦截设置操作
set(target, key, newVal, receiver) {
// 如果属性不存在,则说明是在添加新属性,否则是设置已有属性
const type = Object.prototype.hasOwnProperty.call(target, key) ? 'SET' : 'ADD'
// 设置属性值
const res = Reflect.set(target, key, newVal, receiver)
// 将 type 作为第三个参数传递给 trigger 函数
trigger(target, key, type)
return res
},
// 省略其他拦截函数
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
优先使用 Object.prototype.hasOwnProperty 检查当前操作的属性是否已经存在于目标对象上,如果存在,则说明当前操作类型为 'SET',即修改属性值;否则认为当前操作类型为 'ADD',即添加新属性。最后,我们把类型结果 type 作为第三个参数传递给 trigger 函数。
在 trigger 函数内就可以通过类型 type 来区分当前的操作类型,并且只有当操作类型 type 为 'ADD' 时,才会触发与 ITERATE_KEY 相关联的副作用函数重新执行,这样就避免了不必要的性能损耗:
function trigger(target, key, type) {
const depsMap = bucket.get(target)
if (!depsMap) return
const effects = depsMap.get(key)
const effectsToRun = new Set()
effects && effects.forEach(effectFn => {
if (effectFn !== activeEffect) {
effectsToRun.add(effectFn)
}
})
console.log(type, key)
// 只有当操作类型为 'ADD' 时,才触发与 ITERATE_KEY 相关联的副作用函数重新执行
if (type === 'ADD') {
const iterateEffects = depsMap.get(ITERATE_KEY)
iterateEffects && iterateEffects.forEach(effectFn => {
if (effectFn !== activeEffect) {
effectsToRun.add(effectFn)
}
})
}
effectsToRun.forEach(effectFn => {
if (effectFn.options.scheduler) {
effectFn.options.scheduler(effectFn)
} else {
effectFn()
}
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
通常我们会将操作类型封装为一个枚举值,这样无论是对后期代码的维护,还是对代码的清晰度,都是非常有帮助的。例如:
const TriggerType = { SET: 'SET', ADD: 'ADD' }1
2
3
4
# 删除
关于对象的代理,还剩下最后一项工作需要做,即删除属性操作的代理:
delete p.foo
delete 操作符的行为依赖 [[Delete]] 内部方法,该内部方法可以使用 deleteProperty 拦截:
const p = new Proxy(obj, {
deleteProperty(target, key) {
// 检查被操作的属性是否是对象自己的属性
const hadKey = Object.prototype.hasOwnProperty.call(target, key)
// 使用 Reflect.deleteProperty 完成属性的删除
const res = Reflect.deleteProperty(target, key)
if (res && hadKey) {
// 只有当被删除的属性是对象自己的属性并且成功删除时,才触发更新
trigger(target, key, 'DELETE')
}
return res
}
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
首先检查被删除的属性是否属于对象自身,然后调用Reflect.deleteProperty 函数完成属性的删除工作,只有当这两步的结果都满足条件时,才调用 trigger 函数触发副作用函数重新执行。
注意,在调用 trigger 函数时,我们传递了新的操作类型 'DELETE'。由于删除操作会使得对象的键变少,它会影响 for...in 循环的次数,因此当操作类型为 'DELETE' 时,我们也应该触发那些与 ITERATE_KEY 相关联的副作用函数重新执行:
function trigger(target, key, type) {
const depsMap = bucket.get(target)
if (!depsMap) return
const effects = depsMap.get(key)
const effectsToRun = new Set()
effects && effects.forEach(effectFn => {
if (effectFn !== activeEffect) {
effectsToRun.add(effectFn)
}
})
// 当操作类型为 ADD 或 DELETE 时,需要触发与 ITERATE_KEY 相关联的副作用函数重新执行
if (type === 'ADD' || type === 'DELETE') {
const iterateEffects = depsMap.get(ITERATE_KEY)
iterateEffects && iterateEffects.forEach(effectFn => {
if (effectFn !== activeEffect) {
effectsToRun.add(effectFn)
}
})
}
effectsToRun.forEach(effectFn => {
if (effectFn.options.scheduler) {
effectFn.options.scheduler(effectFn)
} else {
effectFn()
}
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
添加了 type === 'DELETE' 判断,使得删除属性操作能够触发与 ITERATE_KEY 相关联的副作用函数重新执行。
总结
对于一个普通对象来说,只有当添加或删除属性值时才会影响 for...in 循环的结果(它们会影响对象键值数量/长度)。所以当添加或删除属性操作发生时,我们需要取出与 ITERATE_KEY 相关联的副作用函数重新执行。
# 合理地触发响应
# 值未变,不触发
当值没有发生变化时,应该不需要触发响应才对
const obj = { foo: 1 }
const p = new Proxy(obj, { /* ... */ })
effect(() => {
console.log(p.foo)
})
// 设置 p.foo 的值,但值没有变化
p.foo = 1
2
3
4
5
6
7
8
9
p.foo 的初始值为 1,当为 p.foo 设置新的值时,如果值没有发生变化,则不需要触发响应。
# 全等比较
为了满足需求,我们需要修改 set 拦截函数的代码,在调用 trigger 函数触发响应之前,需要检查值是否真的发生了变化:
const p = new Proxy(obj, {
set(target, key, newVal, receiver) {
// 先获取旧值
const oldVal = target[key]
const type = Object.prototype.hasOwnProperty.call(target, key) ? 'SET' : 'ADD'
const res = Reflect.set(target, key, newVal, receiver)
// 比较新值与旧值,只要当不全等的时候才触发响应
if (oldVal !== newVal) {
trigger(target, key, type)
}
return res
},
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
我们在 set 拦截函数内首先获取旧值 oldVal,接着比较新值与旧值,只有当它们不全等的时候才触发响应。
# NaN 特殊处理
然而,仅仅进行全等比较是有缺陷的,这体现在对 NaN 的处理上。我们知道NaN 与 NaN 进行全等比较总会得到 false:
NaN === NaN // false
NaN !== NaN // true
2
如果 p.foo 的初始值是 NaN,并且后续又为其设置了 NaN 作为新值,那么仅仅进行全等比较的缺陷就暴露了:
const obj = { foo: NaN } const p = new Proxy(obj, { /* ... */ }) effect(() => { console.log(p.foo) }) // 仍然会触发响应,因为 NaN !== NaN 为 true p.foo = NaN1
2
3
4
5
6
7
8
9这仍然会触发响应,并导致不必要的更新。
为了解决这个问题,我们需要再加一个条件,即在新值和旧值不全等的情况下,要保证它们都不是 NaN:
const p = new Proxy(obj, {
set(target, key, newVal, receiver) {
// 先获取旧值
const oldVal = target[key]
const type = Object.prototype.hasOwnProperty.call(target, key) ? 'SET' : 'ADD'
const res = Reflect.set(target, key, newVal, receiver)
// 比较新值与旧值,只有当它们不全等,并且不都是 NaN 的时候才触发响应
if (oldVal !== newVal && (oldVal === oldVal || newVal === newVal)) {
trigger(target, key, type)
}
return res
},
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
这样我们就解决了 NaN 的问题。但想要合理地触发响应,仅仅处理关于 NaN 问题还不够。接下来,我们讨论一种从原型上继承属性的情况。
# 原型继承
为了后续理解方便,我们需要封装一个 reactive 函数,该函数接收一个对象作为参数,并返回为其创建的响应式数据:
function reactive (obj) { return new Proxy(obj, { // 拦截读取操作 get (target, key, receiver) { track(target, key) // 返回属性值 return Reflect.get(target, key, receiver) }, // 拦截设置操作 set (target, key, newVal, receiver) { // 先获取旧值 const oldVal = target[key] // 如果属性不存在,则说明是在新增属性 // 否则是修改属性 const type = Object.prototype.hasOwnProperty.call(target, key) ? TriggerType.SET : TriggerType.ADD // 设置属性值 const res = Reflect.set(target, key, newVal, receiver) // 比较新值与旧值,只有当不全等的时候 // 并且它们都不是 NaN 时才触发响应 if ( oldVal !== newVal && ( oldVal === oldVal || newVal === newVal ) ) { // 将 type 作为第三个参数传递给 trigger() 函数 trigger(target, key, type) } return res }, ownKeys (target) { // 将副作用函数与 ITERATE_KEY 关联 track(target, ITERATE_KEY) return Reflect.ownKeys(target) }, deleteProperty (target, key) { // 检查被操作的属性是否是对象自己的属性 const hadKey = Object.prototype.hasOwnProperty.call(target, key) const res = Reflect.deleteProperty(target, key) if (res && hadKey) { // 只有当被删除的属性是对象自己的属性并且成功删除时,才触发更新 trigger(target, key, 'DELETE') } return res }, // 拦截函数调用 apply (target, thisArg, argsList) { Reflect.apply(target, thisArg, argsList) } }) }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66reactive 函数只是对 Proxy 进行了一层封装。
我们基于reactive 创建一个例子:
const obj = {}
const proto = { bar: 1 }
const child = reactive(obj)
const parent = reactive(proto)
// 使用 parent 作为 child 的原型
Object.setPrototypeOf(child, parent)
effect(() => {
console.log(child.bar) // 1
})
// 修改 child.bar 的值
child.bar = 2 // 会导致副作用函数重新执行两次
2
3
4
5
6
7
8
9
10
11
12
child 本身并没有 bar 属性,因此当访问 child.bar 时,值是从原型上继承而来的。但无论如何,既然 child 是响应式数据,那么它与副作用函数之间就会建立联系,因此当我们执行 child.bar = 2 时,期望副作用函数会重新执行。但运行以上代码,会发现副作用函数不仅执行了,还执行了两次,这会造成不必要的更新。
当我们运行时,会发现副作用函数执行了两次,这是为什么呢?我们来分析一下,
① 当在副作用函数中读取 child.bar 的值时,会触发 child 代理对象的 get 拦截函数。在拦截函数内是使用 Reflect.get(target, key, receiver) 来得到最终结果的的,对应到上例, 这句话相当于:
Reflect.get(obj, 'bar', receiver)
② 这其实是实现了通过 obj.bar 来访问属性值的默认行为。也就是说,引擎内部是通过调用 obj 对象所部署的 [[Get]] 内部方法来得到最终结果的。在 [[Get]] 内部方法的执行流程中,如果对象自身不存在该属性,那么会获取对象的原型,并调用原型的 [[Get]] 方法得到最终结果。
对应到上例中,当读取 child.bar 属性值时,由于 child 代理的对象 obj 自身没有 bar 属性,因此会获取对象 obj 的原型,也就是 parent 对象,所以最终得到的实际上是 parent.bar 的值。
而 parent 本身也是响应式数据,因此在副作用函数中访问 parent.bar 的值时,会导致副作用函数被收集,从而也建立响应联系。
所以我们可以得出个结论:child.bar 和 parent.bar 都与副作用函数建立了响应联系。
但这仍然解释不了为什么当设置 child.bar 的值时,会连续触发两次副作用函数执行。
在 set() 拦截函数内,我们使用了 Reflect.set(target, key, newVal, receiver) 来完成默认的行为,即引擎会调用 obj 对象部署的 [[Set]] 内部方法,如果设置的值不存在于该对象上,那么会取其原型,并调用原型的 [[Set]] 方法,这就和 [[Get]] 的流程一样了。
③ 当执行 child.bar = 2 时,会调用 child 代理对象的 set 拦截函数。同样,在 set 拦截函数内,我们使用 Reflect.set(target, key, newVal, receiver) 来完成默认的设置行为,即引擎会调用 obj 对象部署的 [[Set]] 内部方法。在 [[Set]] 内部方法的执行流程中,如果设置的属性不存在于对象上,那么会取得其原型,并调用原型的 [[Set]] 方法,也就是 parent 的 [[Set]] 内部方法。
虽然我们操作的是child.bar,但这也会导致 parent 代理对象的 set 拦截函数被执行。前面提到,当读取 child.bar 的值时,副作用函数不仅会被 child.bar 收集,也会被 parent.bar 收集。所以当 parent 代理对象的 set 拦截函数执行时,就会触发副作用函数重新执行,这就是为什么修改 child.bar 的值会导致副作用函数重新执行两次。
两次更新是由于 set 拦截函数被触发了两次导致的,所以只要我们能够在 set 拦截函数内区分这两次更新,并屏蔽其中一次就可以了。
当我们设置child.bar 的值时,会执行 child 代理对象的 set 拦截函数:
// child 的 set 拦截函数
set(target, key, value, receiver) {
// target 是原始对象 obj
// receiver 是代理对象 child
}
2
3
4
5
此时的 target 是原始对象 obj,receiver 是代理对象 child,receiver 其实就是 target 的代理对象。但由于 obj 上不存在 bar 属性,所以会取得 obj 的原型 parent,并执行 parent 代理对象的 set 拦截函数:
// parent 的 set 拦截函数
set(target, key, value, receiver) {
// target 是原始对象 proto
// receiver 仍然是代理对象 child
}
2
3
4
5
当 parent 代理对象的 set 拦截函数执行时,此时 target 是原始对象 proto,而 receiver 仍然是代理对象 child,而不再是 target 的代理对象。
注意:target 代表谁提供了这个属性,receiver 代表谁访问这个属性。child.bar 是通过代理对象 child 来读取 bar 属性,所以 receiver 指向 child,而 child 的原始对象 obj 本身没有 bar 属性,需要从原型链上找,最终在代理对象 parent 上找到,由 parent 的原始对象 proto 提供这个属性,所以 target 指向 proto。
我们在 set 拦截函数中看看两次的拦截会有什么异同点
const obj = { name: 'obj' } const proto = { name: 'proto', bar: 1 } const child = reactive(obj) child.name = 'child' const parent = reactive(proto) parent.name = 'parent' // 使用 parent 作为 child 的原型 Object.setPrototypeOf(child, parent) effect(() => { console.log(child.bar) }) child.bar = 21
2
3
4
5
6
7
8
9
10
11
12
13
14 控制台输出如下:
{name: 'obj'} Proxy {name: 'obj'} {name: 'proto', bar: 1} Proxy {name: 'proto', bar: 1} 1 {name: 'child'} Proxy {name: 'child'} {name: 'parent', bar: 1} Proxy {name: 'child'} 2 21
2
3
4
5
6
7
8第一次
set()函数执行时,target 是原始对象 obj,receiver 是代理对象 child,我们发现 receiver 是 target 的代理对象;第二次
set()函数执行时,target 是原始对象 proto,receiver 是仍然代理对象 child,而不再是 target 的代理对象。通过这个特点,我们可以看到 target 和 receiver 的区别。
receiver 是方法中 this 指向的对象,也就是代理对象本身,不管经历几级原型链的查找它永远不变,永远都是那个代理对象。
由于我们最初设置的是 child.bar 的值,所以无论在什么情况下,receiver 都是 child,而 target 则是变化的。根据这个区别,我们只需要判断 receiver 是否是 target 的代理对象即可。只有当 receiver 是 target 的代理对象时才触发更新,这样就能够屏蔽由原型引起的更新了。
所以问题变成了如何确定 receiver 是不是 target 的代理对象,这需要我们为 get 拦截函数添加一个能力,让代理对象可以通过 raw 属性读取原始数据:
function reactive(obj) {
return new Proxy(obj {
get(target, key, receiver) {
// 代理对象可以通过 raw 属性访问原始数据
if (key === 'raw') {
return target
}
track(target, key)
return Reflect.get(target, key, receiver)
}
// 省略其他拦截函数
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
例如:
child.raw === obj // true parent.raw === proto // true1
2
有了它,我们就能够在 set 拦截函数中判断 receiver 是不是 target 的代理对象了:
function reactive(obj) {
return new Proxy(obj {
set(target, key, newVal, receiver) {
const oldVal = target[key]
const type = Object.prototype.hasOwnProperty.call(target, key) ? 'SET' : 'ADD'
const res = Reflect.set(target, key, newVal, receiver)
// target === receiver.raw 说明 receiver 就是 target 的代理对象
if (target === receiver.raw) {
if (oldVal !== newVal && (oldVal === oldVal || newVal === newVal)) {
trigger(target, key, type)
}
}
return res
}
// 省略其他拦截函数
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
新增了一个判断条件,只有当 receiver 是 target 的代理对象时才触发更新,这样就能屏蔽由原型引起的更新,从而避免不必要的更新操作。
# 浅响应与深响应
实际上,我们目前所实现的 reactive 是浅响应的。例如,创建 obj 代理对象,该对象的 foo 属性值也是一个对象,即 { bar: 1 }。接着,在副作用函数内访问 obj.foo.bar 的值:
const obj = reactive({ foo: { bar: 1 } })
effect(() => {
console.log(obj.foo.bar)
})
// 修改 obj.foo.bar 的值,并不能触发响应
obj.foo.bar = 2
2
3
4
5
6
7
我们发现,后续对 obj.foo.bar 的修改不能触发副作用函数重新执行,这是为什么呢?来看一下现在的实现:
function reactive(obj) {
return new Proxy(obj {
get(target, key, receiver) {
if (key === 'raw') {
return target
}
track(target, key)
// 当读取属性值时,直接返回结果
return Reflect.get(target, key, receiver)
}
// 省略其他拦截函数
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
当我们读取 obj.foo.bar 时,首先要读取 obj.foo 的值。这里我们直接使用 Reflect.get 函数返回 obj.foo 的结果。由于通过 Reflect.get 得到 obj.foo 的结果是一个普通对象,即 { bar: 1 },它并不是一个响应式对象,所以在副作用函数中访问 obj.foo.bar 时,是不能建立响应联系的。
# 深响应
深响应就是将一个对象的属性对象也变成响应式,需要递归处理。
要解决这个问题,我们需要对 Reflect.get 返回的结果做一层包装,读取属性的时候对返回值用 reactive 再包装一下,确保读取到的属性值也是响应数据:
function reactive(obj) {
return new Proxy(obj {
get(target, key, receiver) {
if (key === 'raw') {
return target
}
track(target, key)
// 得到原始值结果
const res = Reflect.get(target, key, receiver)
if (typeof res === 'object' && res !== null) {
// 调用 reactive 将结果包装成响应式数据并返回
return reactive(res)
}
// 返回 res
return res
}
// 省略其他拦截函数
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
当读取属性值时,我们首先检测该值是否是对象,如果是对象,则递归地调用 reactive 函数将其包装成响应式数据并返回。这样当使用obj.foo 读取 foo 属性值时,得到的就会是一个响应式数据,因此再通过obj.foo.bar 读取 bar 属性值时,自然就会建立响应联系。这样,当修改obj.foo.bar 的值时,就能够触发副作用函数重新执行了。
# 浅响应
浅响应指的是只有对象的第一层属性是响应的,
然而,并非所有情况下我们都希望深响应,这就催生了 shallowReactive,即浅响应。例如:
const obj = shallowReactive({ foo: { bar: 1 } })
effect(() => {
console.log(obj.foo.bar)
})
// obj.foo 是响应的,可以触发副作用函数重新执行
obj.foo = { bar: 2 }
// obj.foo.bar 不是响应的,不能触发副作用函数重新执行
obj.foo.bar = 3
2
3
4
5
6
7
8
9
使用 shallowReactive 函数创建了一个浅响应的代理对象obj。可以发现,只有对象的第一层属性是响应的,第二层及更深层次的属性则不是响应的。
实现此功能并不难,首先,我们把对象创建的工作封装到一个新的函数 createReactive 中:
// 封装 createReactive 函数,接收一个参数 isShallow,代表是否为浅响应,默认为 false,即非浅响应
function createReactive(obj, isShallow = false) {
return new Proxy(obj, {
// 拦截读取操作
get(target, key, receiver) {
if (key === 'raw') {
return target
}
const res = Reflect.get(target, key, receiver)
track(target, key)
// 如果是浅响应,则直接返回原始值
if (isShallow) {
return res
}
if (typeof res === 'object' && res !== null) {
return reactive(res)
}
return res
}
// 省略其他拦截函数
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
该函数除了接收原始对象 obj 之外,还接收参数 isShallow,它是一个布尔值,代表是否创建浅响应对象。默认情况下,isShallow 的值为 false,代表创建深响应对象。这里需要注意的是,当读取属性操作发生时,在 get 拦截函数内如果发现是浅响应的,那么直接返回原始数据即可。
有了 createReactive 函数后,我们就可以使用它轻松地实现 reactive 以及 shallowReactive 函数了:
function reactive(obj) {
return createReactive(obj)
}
function shallowReactive(obj) {
return createReactive(obj, true)
}
2
3
4
5
6
# 只读和浅只读
我们希望有一些数据是只读的,当用户尝试修改只读数据时,会收到一条警告信息,这样就实现了对数据的保护。
例如,组件接收到的 props 对象应该是一个只读数据,这时就要用到接下来要讨论的 readonly 函数,它能够将一个数据变成只读的:
const obj = readonly({ foo: 1 }) // 尝试修改数据,会得到警告 obj.foo = 21
2
3
只读本质上也是对数据对象的代理,我们同样可以使用 createReactive 函数来实现:
// 增加第三个参数 isReadonly,代表是否只读,默认为 false,即非只读
function createReactive(obj, isShallow = false, isReadonly = false) {
return new Proxy(obj, {
// 拦截设置操作
set(target, key, newVal, receiver) {
// 如果是只读的,则打印警告信息并返回
if (isReadonly) {
console.warn(`属性 ${key} 是只读的`)
return true
}
const oldVal = target[key]
const type = Object.prototype.hasOwnProperty.call(target, key) ? 'SET' : 'ADD'
const res = Reflect.set(target, key, newVal, receiver)
if (target === receiver.raw) {
if (oldVal !== newVal && (oldVal === oldVal || newVal === newVal)) {
trigger(target, key, type)
}
}
return res
},
deleteProperty(target, key) {
// 如果是只读的,则打印警告信息并返回
if (isReadonly) {
console.warn(`属性 ${key} 是只读的`)
return true
}
const hadKey = Object.prototype.hasOwnProperty.call(target, key)
const res = Reflect.deleteProperty(target, key)
if (res && hadKey) {
trigger(target, key, 'DELETE')
}
return res
}
// 省略其他拦截函数
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
我们为 createReactive 函数增加第三个参数 isReadonly,指定是否创建一个只读的代理对象。还修改了 set 拦截函数和 deleteProperty 拦截函数的实现,因为对于一个对象来说,只读意味着既不可以设置对象的属性值,也不可以删除对象的属性。
如果一个数据是只读的,那就意味着任何方式都无法修改它。因此,没有必要为只读数据建立响应联系。出于这个原因,当在副作用函数中读取一个只读属性的值时,不需要调用 track 函数追踪响应:
const obj = readonly({ foo: 1 })
effect(() => {
obj.foo // 可以读取值,但是不需要在副作用函数与数据之间建立响应联系
})
2
3
4
为了实现该功能,我们需要修改 get 拦截函数的实现:
function createReactive(obj, isShallow = false, isReadonly = false) {
return new Proxy(obj, {
// 拦截读取操作
get(target, key, receiver) {
if (key === 'raw') {
return target
}
// 非只读的时候才需要建立响应联系
if (!isReadonly) {
track(target, key)
}
const res = Reflect.get(target, key, receiver)
if (isShallow) {
return res
}
if (typeof res === 'object' && res !== null) {
return reactive(res)
}
return res
}
// 省略其他拦截函数
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
在 get 拦截函数内检测 isReadonly 变量的值,判断是否是只读的,只有在非只读的情况下才会调用 track 函数建立响应联系。
基于此,我们就可以实现 readonly 函数了:
function readonly(obj) {
return createReactive(obj, false, true /* 只读 */)
}
2
3
然而,上面实现的 readonly 函数更应该叫作 shallowReadonly,因为它没有做到深只读:
const obj = readonly({ foo: { bar: 1 } })
obj.foo.bar = 2 // 仍然可以修改
2
为了实现深只读,我们还应该在 get 拦截函数内递归地调用 readonly 将数据包装成只读的代理对象,并将其作为返回值返回:
function createReactive(obj, isShallow = false, isReadonly = false) {
return new Proxy(obj, {
// 拦截读取操作
get(target, key, receiver) {
if (key === 'raw') {
return target
}
if (!isReadonly) {
track(target, key)
}
const res = Reflect.get(target, key, receiver)
if (isShallow) {
return res
}
if (typeof res === 'object' && res !== null) {
// 如果数据为只读,则调用 readonly 对值进行包装
return isReadonly ? readonly(res) : reactive(res)
}
return res
}
// 省略其他拦截函数
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
我们在返回属性值之前,判断它是否是只读的,如果是只读的,则调用 readonly 函数对值进行包装,并把包装后的只读对象返回。
对于 shallowReadonly,实际上我们只需要修改 createReactive 的第二个参数即可:
function readonly(obj) {
return createReactive(obj, false, true)
}
function shallowReadonly(obj) {
return createReactive(obj, true /* shallow */, true)
}
2
3
4
5
6
7
在 shallowReadonly 函数内调用 createReactive 函数创建代理对象时,将第二个参数 isShallow 设置为 true,这样就可以创建一个浅只读的代理对象了。
# 代理数组
实际上,在 JavaScript 中,数组只是一个特殊的对象而已。数组是一个异质对象,因为数组对象的 [[DefineOwnProperty]] 内部方法与常规对象不同。数组对象除了 [[DefineOwnProperty]] 这个内部方法之外,其他内部方法的逻辑都与常规对象相同。因此,当实现对数组的代理时,用于代理普通对象的大部分代码可以继续使用。
例如,当我们通过索引读取或设置数组元素的值时,代理对象的 get/set 拦截函数也会执行,因此我们不需要做任何额外的工作,就能够让数组索引的读取和设置操作是响应式的了。例如,以下代码能够按预期工作:
const arr = reactive(['foo']) effect(() => { console.log(arr[0]) // 'foo' }) arr[0] = 'bar' // 能够触发响应1
2
3
4
5
6
7
但对数组的操作与对普通对象的操作仍然存在不同,对数组的读取操作要比普通对象丰富得多。
1、对数组元素或属性的所有可能的读取操作如下:
- 通过索引访问数组元素值:arr[0]。
- 访问数组的长度:arr.length。
- 把数组作为对象,使用 for...in 循环遍历。
- 使用 for...of 迭代遍历数组。
- 数组的原型方法,如 concat/join/every/some/find/findIndex/includes 等,以及其他所有不改变原数组的原型方法。
2、对数组元素或属性的设置操作有以下这些:
- 通过索引修改数组元素值:arr[1] = 3。
- 修改数组长度:arr.length = 0。
- 数组的栈方法:push/pop/shift/unshift。
- 修改原数组的原型方法:splice/fill/sort 等。
3、除了通过数组索引修改数组元素值这种基本操作之外,数组本身还有很多会修改原数组的原型方法。调用这些方法也属于对数组的操作,有些方法的操作语义是“读取”,而有些方法的操作语义是“设置”。因此,当这些操作发生时,也应该正确地建立响应联系或触发响应。
从上面列出的这些对数组的操作来看,似乎代理数组的难度要比代理普通对象的难度大很多。但事实并非如此,因为数组本身也是对象,只不过它是异质对象罢了,它与常规对象的差异并不大。因此,大部分用来代理常规对象的代码对于数组也是生效的。
# 数组的索引与 length
当通过数组的索引访问元素的值时,已经能够建立响应联系了:
const arr = reactive(['foo'])
effect(() => {
console.log(arr[0]) // 'foo'
})
arr[0] = 'bar' // 能够触发响应
2
3
4
5
6
7
但通过索引设置数组的元素值与设置对象的属性值仍然存在根本上的不同,因为数组对象部署的内部方法 [[DefineOwnProperty]] 不同于常规对象。实际上,当我们通过索引设置数组元素的值时,会执行数组对象所部署的内部方法 [[Set]],这一步与设置常规对象的属性值一样。根据规范可知,内部方法 [[Set]] 其实依赖于 [[DefineOwnProperty]],到了这里就体现出了差异。
对于数组对象的 [[DefineOwnProperty]],规范中明确说明,如果设置的索引值大于数组当前的长度,那么要更新数组的 length 属性。所以当通过索引设置元素值时,可能会隐式地修改 length 的属性值。因此在触发响应时,也应该触发与 length 属性相关联的副作用函数重新执行,如下面的代码所示:
const arr = reactive(['foo']) // 数组的原长度为 1
effect(() => {
console.log(arr.length) // 1
})
// 设置索引 1 的值,会导致数组的长度变为 2
arr[1] = 'bar'
2
3
4
5
6
7
数组的原长度为 1,并且在副作用函数中访问了 length 属性。然后设置数组索引为 1 的元素值,这会导致数组的长度变为 2,因此应该触发副作用函数重新执行。但目前的实现还做不到这一点,为了实现目标,我们需要修改set 拦截函数:
function createReactive(obj, isShallow = false, isReadonly = false) {
return new Proxy(obj, {
// 拦截设置操作
set(target, key, newVal, receiver) {
if (isReadonly) {
console.warn(`属性 ${key} 是只读的`)
return true
}
const oldVal = target[key]
// 如果属性不存在,则说明是在添加新的属性,否则是设置已有属性
const type = Array.isArray(target)
// 如果代理目标是数组,则检测被设置的索引值是否小于数组长度,
// 如果是,则视作 SET 操作,否则是 ADD 操作
? Number(key) < target.length ? 'SET' : 'ADD'
: Object.prototype.hasOwnProperty.call(target, key) ? 'SET' : 'ADD'
const res = Reflect.set(target, key, newVal, receiver)
if (target === receiver.raw) {
if (oldVal !== newVal && (oldVal === oldVal || newVal === newVal)) {
trigger(target, key, type)
}
}
return res
}
// 省略其他拦截函数
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
在判断操作类型时,新增了对数组类型的判断。如果代理的目标对象是数组,那么对于操作类型的判断会有所区别。即被设置的索引值如果小于数组长度,就视作 SET 操作,因为它不会改变数组长度;如果设置的索引值大于数组的当前长度,则视作 ADD 操作,因为这会隐式地改变数组的 length 属性值。
有了这些信息,我们就可以在 trigger 函数中正确地触发与数组对象的 length 属性相关联的副作用函数重新执行了:
function trigger(target, key, type) {
const depsMap = bucket.get(target)
if (!depsMap) return
// 省略部分内容
// 当操作类型为 ADD 并且目标对象是数组时,应该取出并执行那些与 length 属性相关联的副作用函数
if (type === 'ADD' && Array.isArray(target)) {
// 取出与 length 相关联的副作用函数
const lengthEffects = depsMap.get('length')
// 将这些副作用函数添加到 effectsToRun 中,待执行
lengthEffects && lengthEffects.forEach(effectFn => {
if (effectFn !== activeEffect) {
effectsToRun.add(effectFn)
}
})
}
effectsToRun.forEach(effectFn => {
if (effectFn.options.scheduler) {
effectFn.options.scheduler(effectFn)
} else {
effectFn()
}
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
但是反过来思考,其实修改数组的 length 属性也会隐式地影响数组元素,例如:
const arr = reactive(['foo'])
effect(() => {
// 访问数组的第 0 个元素
console.log(arr[0]) // foo
})
// 将数组的长度修改为 0,导致第 0 个元素被删除,因此应该触发响应
arr.length = 0
2
3
4
5
6
7
8
将数组的 length 属性修改为 0,这会隐式地影响数组元素,即所有元素都被删除,所以应该触发副作用函数重新执行。然而并非所有对 length 属性的修改都会影响数组中的已有元素,拿上例来说,如果我们将 length 属性设置为 100,这并不会影响第 0 个元素,所以也就不需要触发副作用函数重新执行。
当修改 length 属性值时,只有那些索引值大于或等于新的 length 属性值的元素才需要触发响应。但目前的实现还做不到这一点,为了实现目标,我们需要修改 set 拦截函数。在调用 trigger 函数触发响应时,应该把新的属性值传递过去:
function createReactive(obj, isShallow = false, isReadonly = false) {
return new Proxy(obj, {
// 拦截设置操作
set(target, key, newVal, receiver) {
if (isReadonly) {
console.warn(`属性 ${key} 是只读的`)
return true
}
const oldVal = target[key]
const type = Array.isArray(target)
? Number(key) < target.length ? 'SET' : 'ADD'
: Object.prototype.hasOwnProperty.call(target, key) ? 'SET' : 'ADD'
const res = Reflect.set(target, key, newVal, receiver)
if (target === receiver.raw) {
if (oldVal !== newVal && (oldVal === oldVal || newVal === newVal)) {
// 增加第四个参数,即触发响应的新值
trigger(target, key, type, newVal)
}
}
return res
},
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
接着,我们还需要修改 trigger 函数:
// 为 trigger 函数增加第四个参数,newVal,即新值
function trigger(target, key, type, newVal) {
const depsMap = bucket.get(target)
if (!depsMap) return
// 省略其他代码
// 如果操作目标是数组,并且修改了数组的 length 属性
if (Array.isArray(target) && key === 'length') {
// 对于索引大于或等于新的 length 值的元素,
// 需要把所有相关联的副作用函数取出并添加到 effectsToRun 中待执行
depsMap.forEach((effects, key) => {
if (key >= newVal) {
effects.forEach(effectFn => {
if (effectFn !== activeEffect) {
effectsToRun.add(effectFn)
}
})
}
})
}
effectsToRun.forEach(effectFn => {
if (effectFn.options.scheduler) {
effectFn.options.scheduler(effectFn)
} else {
effectFn()
}
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
为 trigger 函数增加了第四个参数,即触发响应时的新值(新的 length 属性值),它代表新的数组长度。接着,我们判断操作的目标是否是数组,如果是,则需要找到所有索引值大于或等于新的 length 值的元素,然后把与它们相关联的副作用函数取出并执行。
# 遍历数组
# 使用 for...in 循环遍历
数组也是对象,意味着同样可以使用 for...in 循环遍历,但我们应该尽量避免使用 for...in 循环遍历数组:
const arr = reactive(['foo'])
effect(() => {
for (const key in arr) {
console.log(key) // 0
}
})
2
3
4
5
6
7
注意:这里不是遍历数组元素,而是索引,因此只需要关心length是否变化。
数组对象和常规对象的不同仅体现在 [[DefineOwnProperty]] 这个内部方法上,也就是说,使用 for...in 循环遍历数组与遍历常规对象并无差异,因此同样可以使用 ownKeys 拦截函数进行拦截。
不过,对于数组来说情况有所不同,下面这些操作会影响 for...in 循环对数组的遍历:
- 添加新元素:arr[100] = bar;
- 修改数组长度:arr.length = 0。
下面是我们之前实现的 ownKeys 拦截函数:
function createReactive(obj, isShallow = false, isReadonly = false) { return new Proxy(obj, { // 省略其他拦截函数 ownKeys(target) { track(target, ITERATE_KEY) return Reflect.ownKeys(target) } }) }1
2
3
4
5
6
7
8
9当初我们为了追踪对普通对象的 for...in 操作,人为创造了 ITERATE_KEY 作为追踪的 key,当添加或删除属性操作发生时,取出与 ITERATE_KEY 相关联的副作用函数重新执行。
无论是为数组添加新元素,还是直接修改数组的长度,本质上都是因为修改了数组的 length 属性。一旦数组的 length 属性被修改,那么 for...in 循环对数组的遍历结果就会改变,所以在这种情况下我们应该触发响应。
我们可以在 ownKeys 拦截函数内,判断当前操作目标 target 是否是数组,如果是,则使用 length 作为 key 去建立响应联系:
function createReactive(obj, isShallow = false, isReadonly = false) {
return new Proxy(obj, {
// 省略其他拦截函数
ownKeys(target) {
// 如果操作目标 target 是数组,则使用 length 属性作为 key 并建立响应联系
track(target, Array.isArray(target) ? 'length' : ITERATE_KEY)
return Reflect.ownKeys(target)
}
})
}
2
3
4
5
6
7
8
9
10
这样无论是为数组添加新元素,还是直接修改 length 属性,都能够正确地触发响应了:
const arr = reactive(['foo'])
effect(() => {
for (const key in arr) {
console.log(key)
}
})
arr[1] = 'bar' // 能够触发副作用函数重新执行
arr.length = 0 // 能够触发副作用函数重新执行
2
3
4
5
6
7
8
9
10
# 使用 for...of 迭代遍历
与 for...in 不同,for...of 是用来遍历可迭代对象(iterable object)的。
可迭代对象:ES2015 为 JavaScript 定义了迭代协议(iteration protocol),它不是新的语法,而是一种协议。具体来说,一个对象能否被迭代,取决于该对象或者该对象的原型是否实现了 @@iterator 方法。这里的 @@[name] 标志在 ECMAScript 规范里用来代指 JavaScript 内建的 symbols 值,例如 @@iterator 指的就是 Symbol.iterator 这个值。
如果一个对象实现了 Symbol.iterator 方法,那么这个对象就是可以迭代的,可以使用 for...of 循环遍历它。
const obj = {
val: 0,
[Symbol.iterator] () {
return {
next () {
value: obj.val++,
done: obj.val > 10 ? true : false
}
}
}
}
// 该对象实现了 Symbol.iterator 方法,因此可以使用 for...of 循环遍历它:
for (const value of obj) {
console.log(value) // 0 1 2 3 4 5 6 7 8 9
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
数组内建了 Symbol.iterator 方法的实现(内建了迭代器方法),我们可以做一个实验:
const arr = [1, 2, 3, 4, 5]
// 获取并调用数组内建的迭代器方法
const itr = arr[Symbol.iterator]()
console.log(itr.next()) // {value: 1, done: false}
console.log(itr.next()) // {value: 2, done: false}
console.log(itr.next()) // {value: 3, done: false}
console.log(itr.next()) // {value: 4, done: false}
console.log(itr.next()) // {value: 5, done: false}
console.log(itr.next()) // {value: undefined, done: true}
2
3
4
5
6
7
8
9
10
可以看到,我们能够通过将 Symbol.iterator 作为键,获取数组内建的迭代器方法。然后手动执行迭代器的 next 函数,这样也可以得到期望的结果。
这也是默认情况下数组可以使用 for...of 遍历的原因:
const arr = [1, 2, 3, 4, 5]
for (const val of arr) {
console.log(val) // 1, 2, 3, 4, 5
}
2
3
4
在数组迭代器的执行流程中,会读取数组的 length 属性,如果迭代的是数组元素值,还会读取数组的索引。
我们可以给出一个数组迭代器的模拟实现:
const arr = [1, 2, 3, 4, 5]
arr[Symbol.iterator] = function() {
const target = this
const len = target.length
let index = 0
return {
next() {
return {
value: index < len ? target[index] : undefined,
done: index++ >= len
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
我们用自定义的实现覆盖了数组内建的迭代器方法,但它仍然能够正常工作。
这个例子表明,迭代数组时,只需要在副作用函数与数组的长度和索引之间建立响应联系,就能够实现响应式的 for...of 迭代:
const arr = reactive([1, 2, 3, 4, 5])
effect(() => {
for (const val of arr) {
console.log(val)
}
})
arr[1] = 'bar' // 能够触发响应
arr.length = 0 // 能够触发响应
2
3
4
5
6
7
8
9
10
可以看到,不需要增加任何代码就能够使其正确地工作。这是因为只要数组的长度和元素值发生改变,副作用函数自然会重新执行。
数组的 values 方法的返回值实际上就是数组内建的迭代器,我们可以验证这一点:
console.log(Array.prototype.values === Array.prototype[Symbol.iterator]) // true
换句话说,在不增加任何代码的情况下,我们也能够让数组的迭代器方法正确地工作:
const arr = reactive([1, 2, 3, 4, 5]) effect(() => { for (const val of arr.values()) { console.log(val) } }) arr[1] = 'bar' // 能够触发响应 arr.length = 0 // 能够触发响应1
2
3
4
5
6
7
8
9
10
对数组的响应式的额外处理,需要避免在副作用函数和 Symbol.iterator 这类 symbol 值之间建立响应联系。只需要监听 length 属性变化即可响应 for...in 循环,无需监听其他内置属性。
无论是使用 for...of 循环,还是调用 values 等方法,它们都会读取数组的 Symbol.iterator 属性,并建立依赖。该属性是一个 symbol 值,为了避免发生意外的错误,以及性能上的考虑,我们不应该在副作用函数与 Symbol.iterator 这类 symbol 值之间建立响应联系,不符合预期的联系应该去掉。
修改 get 拦截函数,在调用 track 函数进行追踪之前,添加一个判断条件,即只有当 key 的类型不是 symbol 时才进行追踪,这样就避免了上述问题:
function createReactive(obj, isShallow = false, isReadonly = false) {
return new Proxy(obj, {
// 拦截读取操作
get(target, key, receiver) {
console.log('get: ', key)
if (key === 'raw') {
return target
}
// 添加判断,如果 key 的类型是 symbol,则不进行追踪
if (!isReadonly && typeof key !== 'symbol') {
track(target, key)
}
const res = Reflect.get(target, key, receiver)
if (isShallow) {
return res
}
if (typeof res === 'object' && res !== null) {
return isReadonly ? readonly(res) : reactive(res)
}
return res
},
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
应该在数组元素或长度发生变化的时候触发响应,symbol 属性是 javascript 内部调用的,同样会触发 get 建立响应联系,但是对于用户来说,这个响应是“意外”的。所以对 symbol 进行特殊处理,不做响应式跟踪。
# 数组的查找方法
数组的方法内部其实都依赖了对象的基本语义。所以大多数情况下,我们不需要做特殊处理即可让这些方法按预期工作。例如:
const arr = reactive([1, 2])
effect(() => {
console.log(arr.includes(1)) // 初始打印 true
})
arr[0] = 3 // 副作用函数重新执行,并打印 false
2
3
4
5
6
7
这是因为 includes 方法为了找到给定的值,它内部会访问数组的 length 属性以及数组的索引,因此当我们修改某个索引指向的元素值后能够触发响应。
然而 includes 方法并不总是按照预期工作,举个例子:
const obj = {}
const arr = reactive([obj])
console.log(arr.includes(arr[0])) // false
2
3
4
很显然,这个操作应该返回true,但是它却返回了 false。
includes 整个过程对 arr[0] 有两次访问,并对两次访问结果作对比。因为每次访问都对结果作了响应式包装,相当于每次返回的都是一个新的代理对象。
在 includes 方法的执行流程中,会通过索引读取数组元素的值。通过代理对象来访问元素值时,如果值仍然是可以被代理的,那么得到的值就是新的代理对象而非原始对象。下面这段 get 拦截函数内的代码可以证明这一点:
if (typeof res === 'object' && res !== null) {
// 如果值可以被代理,则返回代理对象
return isReadonly ? readonly(res) : reactive(res)
}
2
3
4
再回头看这句代码:arr.includes(arr[0]),arr[0] 得到的是一个代理对象,而在 includes 方法内部也会通过 arr 访问数组元素,从而也得到一个代理对象,问题是这两个代理对象是不同的。这是因为每次调用 reactive函数时都会创建一个新的代理对象:
function reactive(obj) {
// 每次调用 reactive 时,都会创建新的代理对象
return createReactive(obj)
}
2
3
4
即使参数 obj 是相同的,每次调用 reactive 函数时,也都会创建新的代理对象。
这个问题的解决方案如下所示(用一个 map 存起来):
// 定义一个 Map 实例,存储原始对象到代理对象的映射
const reactiveMap = new Map()
function reactive(obj) {
// 优先通过原始对象 obj 寻找之前创建的代理对象,如果找到了,直接返回已有的代理对象
const existionProxy = reactiveMap.get(obj)
if (existionProxy) return existionProxy
// 否则,创建新的代理对象
const proxy = createReactive(obj)
// 存储到 Map 中,从而避免重复创建
reactiveMap.set(obj, proxy)
return proxy
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
定义了 reactiveMap,用来存储原始对象到代理对象的映射。每次调用 reactive 函数创建代理对象之前,优先检查是否已经存在相应的代理对象,如果存在,则直接返回已有的代理对象,这样就避免了为同一个原始对象多次创建代理对象的问题。
接下来,我们再次运行前面提到的例子:
const obj = {}
const arr = reactive([obj])
console.log(arr.includes(arr[0])) // true
2
3
4
可以发现,此时的行为已经符合预期了。
然而,还不能高兴得太早,再来看下面的代码:
const obj = {}
const arr = reactive([obj])
console.log(arr.includes(obj)) // false
2
3
4
此时,因为 includes内部的 this 指向的是代理对象 arr,并且在获取数组元素时得到的值也是代理对象,所以拿原始对象 obj 去查找肯定找不到,因此返回 false。
为此,我们需要重写数组的 includes 方法并实现自定义的行为,才能解决这个问题。
首先,我们修改了 get 拦截函数,目的是重写数组的 includes 方法,如下面的代码所示:
const arrayInstrumentations = {
includes: function() {/* ... */}
}
function createReactive(obj, isShallow = false, isReadonly = false) {
return new Proxy(obj, {
// 拦截读取操作
get(target, key, receiver) {
console.log('get: ', key)
if (key === 'raw') {
return target
}
// 如果操作的目标对象是数组,并且 key 存在于 arrayInstrumentations 上,
// 那么返回定义在 arrayInstrumentations 上的值
if (Array.isArray(target) && arrayInstrumentations.hasOwnProperty(key)) {
return Reflect.get(arrayInstrumentations, key, receiver)
}
if (!isReadonly && typeof key !== 'symbol') {
track(target, key)
}
const res = Reflect.get(target, key, receiver)
if (isShallow) {
return res
}
if (typeof res === 'object' && res !== null) {
return isReadonly ? readonly(res) : reactive(res)
}
return res
},
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
includes 是属性也是函数,arr.includes 可以理解为读取代理对象 arr 的includes 属性,这就会触发 get 拦截函数,在该函数内检查 target 是否是数组,如果是数组并且读取的键值 key 存在于 arrayInstrumentations 上,则返回定义在 arrayInstrumentations 对象上相应的值。
也就是说,当执行 arr.includes 时,实际执行的是定义在 arrayInstrumentations 上的 includes 函数,这样就实现了重写。arrayInstrumentations 用来保存所有重写的数组方法。
接下来,我们就可以自定义 includes 函数了(arrayInstrumentations 上的/重写数组的 includes 方法):
const originMethod = Array.prototype.includes
const arrayInstrumentations = {
includes: function(...args) {
// this 是代理对象,先在代理对象中查找,将结果存储到 res 中
let res = originMethod.apply(this, args)
if (res === false) {
// res 为 false 说明没找到,通过 this.raw 拿到原始数组,再去其中查找并更新 res 值
res = originMethod.apply(this.raw, args)
}
// 返回最终结果
return res
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
includes 方法内的 this 指向的是代理对象,我们先在代理对象中进行查找,这其实是实现了 arr.include(obj) 的默认行为。如果找不到,通过 this.raw 拿到原始数组,再去其中查找,最后返回结果,这样就解决了上述问题。
可以发现,现在代码的行为已经符合预期了:
const obj = {}
const arr = reactive([obj])
console.log(arr.includes(obj)) // true
2
3
4
除了 includes 方法之外,还需要做类似处理的数组方法有 indexOf 和lastIndexOf,因为它们都属于根据给定的值返回查找结果的方法。完整的代码如下:
const arrayInstrumentations = {}
;['includes', 'indexOf', 'lastIndexOf'].forEach(method => {
const originMethod = Array.prototype[method]
arrayInstrumentations[method] = function(...args) {
// this 是代理对象,先在代理对象中查找,将结果存储到 res 中
let res = originMethod.apply(this, args)
if (res === false || res === -1) {
// res 为 false 说明没找到,通过 this.raw 拿到原始数组,再去其中查找,并更新 res 值
res = originMethod.apply(this.raw, args)
}
// 返回最终结果
return res
}
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
重写数组中的 includes 和 indexof 等方法,
在代理对象中寻找一个原始对象属性,因为里面的属性都会被 proxy 包裹起来,使用原对象寻找是找不到的。所以需要重写 includes 等方法,这样,在 proxy 内找不到,就去被代理的原始对象上找,问题就解决了。
# 隐式修改数组长度的原型方法
那些会隐式修改数组长度的方法,主要指的是数组的栈方法,例如 push/pop/shift/unshift。除此之外,splice 方法也会隐式地修改数组长度。
在 push 方法的执行流程中,既会读取数组的 length 属性值,也会设置数组的 length 属性值。这会导致两个独立的副作用函数互相影响。例如,运行以下这段测试代码,会得到栈溢出的错误:
const arr = reactive([])
// 第一个副作用函数
effect(() => {
arr.push(1)
})
// 第二个副作用函数
effect(() => {
arr.push(1)
})
2
3
4
5
6
7
8
9
10
● 第一个副作用函数执行,调用数组的 push 方法会间接读取数组的 length 属性。所以,当第一个副作用函数执行完毕后,会与 length 属性建立响应联系。
●第二个副作用函数执行,它也会与 length 属性建立响应联系。但调用 arr.push 方法不仅会间接读取数组的 length 属性,还会间接设置 length 属性的值。
● 第二个函数内的 arr.push 方法的调用设置了数组的 length 属性值。于是,响应系统尝试把与 length 属性相关联的副作用函数全部取出并执行,其中就包括第一个副作用函数。问题就出在这里,可以发现,第二个副作用函数还未执行完毕,就要再次执行第一个副作用函数了。
● 第一个副作用函数再次执行。同样,这会间接设置数组的 length 属性。于是,响应系统又要尝试把所有与 length 属性相关联的副作用函数取出并执行,其中就包含第二个副作用函数。
● 如此循环往复,最终导致调用栈溢出。
问题的原因是 push 方法的调用会间接读取 length 属性。所以,只要我们“屏蔽”对 length 属性的读取,从而避免在它与副作用函数之间建立响应联系,问题就迎刃而解了。因为数组的 push 方法在语义上是修改操作,而非读取操作,所以避免建立响应联系并不会产生其他副作用。这需要重写数组的 push 方法:
// 一个标记变量,代表是否进行追踪。默认值为 true,即允许追踪
let shouldTrack = true
// 重写数组的 push 方法
;['push'].forEach(method => {
// 取得原始 push 方法
const originMethod = Array.prototype[method]
// 重写
arrayInstrumentations[method] = function(...args) {
// 在调用原始方法之前,禁止追踪
shouldTrack = false
// push 方法的默认行为
let res = originMethod.apply(this, args)
// 在调用原始方法之后,恢复原来的行为,即允许追踪
shouldTrack = true
return res
}
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
定义了一个标记变量 shouldTrack,它是一个布尔值,代表是否允许追踪。在执行默认行为之前,先将标记变量 shouldTrack 的值设置为 false,即禁止追踪。当push 方法的默认行为执行完毕后,再将标记变量 shouldTrack 的值还原为true,代表允许追踪。
最后,还需要修改 track 函数:
function track(target, key) {
// 当禁止追踪时,直接返回
if (!activeEffect || !shouldTrack) return
// 省略部分代码
}
2
3
4
5
当标记变量 shouldTrack 的值为 false 时,即禁止追踪时,track 函数会直接返回。这样,当 push 方法间接读取 length 属性值时,由于此时是禁止追踪的状态,所以 length 属性与副作用函数之间不会建立响应联系。这样就实现了前文给出的方案。
对 push 方法的处理:避免因读取 length 而与 length 建立依赖。 解决方法:引入全局变量控制是否进行 track。
当我们再次尝试运行前面给出的测试代码,会发现它能够正确地工作,并且不会导致调用栈溢出。
除了 push 方法之外,pop、shift、unshift 以及 splice 等方法都需要做类似的处理。完整的代码如下:
let shouldTrack = true
// 重写数组的 push、pop、shift、unshift 以及 splice 方法
;['push', 'pop', 'shift', 'unshift', 'splice'].forEach(method => {
const originMethod = Array.prototype[method]
arrayInstrumentations[method] = function(...args) {
shouldTrack = false
let res = originMethod.apply(this, args)
shouldTrack = true
return res
}
})
2
3
4
5
6
7
8
9
10
11
# 代理 Set 和 Map
集合类型包括 Map/Set 以及 WeakMap/WeakSet。使用 Proxy 代理集合类型的数据不同于代理普通对象,因为集合类型数据的操作与普通对象存在很大的不同。
# Set
Set 类型的原型属性和方法如下。
- size:返回集合中元素的数量。
- add(value):向集合中添加给定的值。
- clear():清空集合。
- delete(value):从集合中删除给定的值。
- has(value):判断集合中是否存在给定的值。
- keys():返回一个迭代器对象。可用于 for...of 循环,迭代器对象产生的值为集合中的元素值。
- values():对于 Set 集合类型来说,keys() 与 values() 等价。
- entries():返回一个迭代器对象。迭代过程中为集合中的每一个元素产生一个数组值 [value, value]。
- ● forEach(callback[, thisArg]):forEach 函数会遍历集合中的所有元素,并对每一个元素调用 callback 函数。forEach 函数接收可选的第二个参数 thisArg,用于指定 callback 函数执行时的 this 值。
# Map
Map 类型的原型属性和方法如下。
- size:返回 Map 数据中的键值对数量。
- clear():清空 Map。
- delete(key):删除指定 key 的键值对。
- has(key):判断 Map 中是否存在指定 key 的键值对。
- get(key):读取指定 key 对应的值。
- set(key, value):为 Map 设置新的键值对。
- keys():返回一个迭代器对象。迭代过程中会产生键值对的 key 值。
- values():返回一个迭代器对象。迭代过程中会产生键值对的 value 值。
- entries():返回一个迭代器对象。迭代过程中会产生由 [key, value] 组成的数组值。
- forEach(callback[, thisArg]):forEach 函数会遍历 Map 数据的所有键值对,并对每一个键值对调用 callback 函数。forEach 函数接收可选的第二个参数thisArg,用于指定 callback 函数执行时的 this 值。
Map 和 Set 这两个数据类型的操作方法相似。它们之间最大的不同体现在,Set 类型使用 add(value) 方法添加元素,而 Map 类型使用 set(key, value) 方法设置键值对,并且 Map 类型可以使用 get(key) 方法读取相应的值。
# 如何代理 Set 和 Map
前文讲到,Set 和 Map 类型的数据有特定的属性和方法用来操作自身。这一点与普通对象不同,如下面的代码所示:
// 普通对象的读取和设置操作
const obj = { foo: 1 }
obj.foo // 读取属性
obj.foo = 2 // 设置属性
// 用 get/set 方法操作 Map 数据
const map = new Map()
map.set('key', 1) // 设置数据
map.get('key') // 读取数据
2
3
4
5
6
7
8
9
正是因为这些差异的存在,我们不能像代理普通对象那样代理 Set 和 Map 类型的数据。
但整体思路不变(响应式数据的核心),即当读取操作发生时,应该调用 track 函数建立响应联系;当设置操作发生时,应该调用 trigger 函数触发响应,我们最终要实现的目标如下:
const proxy = reactive(new Map([['key', 1]]))
effect(() => {
console.log(proxy.get('key')) // 读取键为 key 的值
})
proxy.set('key', 2) // 修改键为 key 的值,应该触发响应
2
3
4
5
但在动手实现之前,我们有必要先了解关于使用 Proxy 代理 Set 或 Map 类型数据的注意事项。先来看一段代码:
const s = new Set([1, 2, 3])
const p = new Proxy(s, {})
console.log(p.size) // 报错 TypeError: Method get Set.prototype.size called on incompatible receiver
2
3
4
由于代理的目标对象是 Set 类型,因此我们可以通过读取它的 p.size 属性获取元素的数量。但不幸的是,我们得到了一个错误。错误信息的大意是“在不兼容的 receiver 上调用了 get Set.prototype.size 方法”。由此我们大概能猜到,size 属性应该是一个访问器属性,所以它作为方法被调用了。
通过查阅规范,我们知道 Set.prototype.size 是一个访问器属性,它的 set 访问器函数是 undefined,它的 get 访问器函数执行过程中,首先会让 S 的值为 this,**由于我们是通过代理对象 p 来访问 size 属性的,所以 this 就是代理对象 p。**然后调用抽象方法 RequireInternalSlot(S, [[SetData]]) 来检查 S 是否存在内部槽 [[SetData]]。很显然,代理对象 S 不存在 [[SetData]] 这个内部槽,于是会抛出一个错误,也就是前面例子中得到的错误。
Proxy 是没有 [[SetData]] 内部槽的,只有 Set 的实例有,所以针对访问 size 属性的情况,需要把 receiver 设置为 target 本身。为了修复这个问题,我们需要修正访问器属性的 getter 函数执行时的 this 指向:
const s = new Set([1, 2, 3])
const p = new Proxy(s, {
get(target, key, receiver) {
if (key === 'size') {
// 如果读取的是 size 属性
// 通过指定第三个参数 receiver 为原始对象 target 从而修复问题
return Reflect.get(target, key, target)
}
// 读取其他属性的默认行为
return Reflect.get(target, key, receiver)
}
})
console.log(s.size) // 3
2
3
4
5
6
7
8
9
10
11
12
13
14
在创建代理对象时增加了 get 拦截函数。然后检查读取的属性名称是不是 size,如果是,则在调用 Reflect.get 函数时指定第三个参数为原始 Set 对象,这样访问器属性 size 的 getter 函数在执行时,其 this 指向的就是原始 Set 对象而非代理对象了。由于原始 Set 对象上存在 [[SetData]] 内部槽,因此程序得以正确运行。
接着,我们再来尝试从 Set 中删除数据:
const s = new Set([1, 2, 3])
const p = new Proxy(s, {
get(target, key, receiver) {
if (key === 'size') {
return Reflect.get(target, key, target)
}
// 读取其他属性的默认行为
return Reflect.get(target, key, receiver)
}
}
)
// 调用 delete 方法删除值为 1 的元素
// 会得到错误 TypeError: Method Set.prototype.delete called on incompatible receiver [object Object]
p.delete(1)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
调用 p.delete 方法时会得到一个错误,这个错误与前文讲解的访问p.size 属性时发生的错误非常相似。
实际上,访问 p.size 与访问 p.delete 是不同的。这是因为 size 是属性,是一个访问器属性,而 delete 是一个方法。当访问 p.size 时,访问器属性的 getter 函数会立即执行,此时我们可以通过修改 receiver 来改变 getter 函数的 this 的指向。
而当访问 p.delete 时,delete 方法并没有执行,真正使其执行的语句是p.delete(1) 这句函数调用。因此,无论怎么修改 receiver,delete 方法执行时的this 都会指向代理对象 p,而不会指向原始 Set 对象。想要修复这个问题也不难,只需要把 delete 方法与原始数据对象绑定即可:
const s = new Set([1, 2, 3])
const p = new Proxy(s, {
get(target, key, receiver) {
if (key === 'size') {
return Reflect.get(target, key, target)
}
// 将方法与原始数据对象 target 绑定后返回
return target[key].bind(target)
}
}
)
// 调用 delete 方法删除值为 1 的元素,正确执行
p.delete(1)
2
3
4
5
6
7
8
9
10
11
12
13
14
我们使用 target[key].bind(target) 代替了Reflect.get(target, key, receiver)。可以看到,我们使用 bind 函数将用于操作数据的方法与原始数据对象 target 做了绑定。这样当 p.delete(1) 语句执行时,delete 函数的 this 总是指向原始数据对象而非代理对象,于是代码能够正确执行。
在普通对象里,删除对象属性用的是 delete obj.xxx,只要拦截 Proxy 的 deleteProperty 属性就可以处理了。但在 Set 里,p.delete 虽然进入了 Proxy 的 getter 属性,但 set.prototype.delete 是一个方法,因此在 Proxy 的 getter 里要将这个方法用 bind 绑定作用域后返回出去。
最后,为了后续讲解方便以及代码的可扩展性,我们将 new Proxy 也封装到前文介绍的 createReactive 函数中:
const reactiveMap = new Map()
// reactive 函数与之前相比没有变化
function reactive(obj) {
const existionProxy = reactiveMap.get(obj)
if (existionProxy) return existionProxy
const proxy = createReactive(obj)
reactiveMap.set(obj, proxy)
return proxy
}
// 在 createReactive 里封装用于代理 Set/Map 类型数据的逻辑
function createReactive(obj, isShallow = false, isReadonly = false) {
return new Proxy(obj, {
get(target, key, receiver) {
if (key === 'size') {
return Reflect.get(target, key, target)
}
return target[key].bind(target)
}
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
这样,我们就可以很简单地创建代理数据了:
const p = reactive(new Set([1, 2, 3]))
console.log(p.size) // 3
2
# 建立响应联系
了解了为 Set 和 Map 类型数据创建代理时的注意事项之后,我们就可以着手实现Set 类型数据的响应式方案了。
以下代码展示了响应式 Set 类型数据的工作方式:
const p = reactive(new Set([1, 2, 3]))
effect(() => {
// 在副作用函数内访问 size 属性
console.log(p.size)
})
// 添加值为 1 的元素,应该触发响应
p.add(1)
2
3
4
5
6
7
8
首先,在副作用函数内访问了p.size 属性;接着,调用 p.add 函数向集合中添加数据。由于这个行为会间接改变集合的 size 属性值,所以我们期望副作用函数会重新执行。
为了实现这个目标,我们需要在访问 size 属性时调用 track 函数进行依赖追踪,然后在 add 方法执行时调用 trigger 函数触发响应。下面的代码展示了如何进行依赖追踪:
function createReactive(obj, isShallow = false, isReadonly = false) {
return new Proxy(obj, {
get(target, key, receiver) {
if (key === 'size') {
// 调用 track 函数建立响应联系
track(target, ITERATE_KEY)
return Reflect.get(target, key, target)
}
return target[key].bind(target)
}
})
}
2
3
4
5
6
7
8
9
10
11
12
13
**当读取 size 属性时,只需要调用 track 函数建立响应联系即可。**响应联系需要建立在 ITERATE_KEY 与副作用函数之间,这是因为任何新增、删除操作都会影响 size 属性。trigger 中对 ITERATE_KEY 做了处理,使用 ITERATE_KEY 方便复用。
读取 size 建立起当前副作用和 ITERATE_KEY 之间的映射关系,后面如果操作是新或者删除,都会把 ITERATE_KEY 集合中的副作用函数拿出来执行。
当调用 add 方法向集合中添加新元素时,应该怎么触发响应呢?很显然,这需要我们实现一个自定义的 add 方法才行:
// 定义一个对象,将自定义的 add 方法定义到该对象下
const mutableInstrumentations = {
add(key) {/* ... */}
}
function createReactive(obj, isShallow = false, isReadonly = false) {
return new Proxy(obj, {
get(target, key, receiver) {
// 如果读取的是 raw 属性,则返回原始数据对象 target
if (key === 'raw') return target
if (key === 'size') {
track(target, ITERATE_KEY)
return Reflect.get(target, key, target)
}
// 返回定义在 mutableInstrumentations 对象下的方法
return mutableInstrumentations[key]
}
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
定义一个对象 mutableInstrumentations,将所有自定义实现的方法都定义到该对象下,例如 mutableInstrumentations.add 方法。在 get 拦截函数内返回定义在 mutableInstrumentations 对象中的方法。这样,当通过p.add 获取方法时,得到的就是我们自定义的 mutableInstrumentations.add 方法了。
有了自定义实现的方法后,就可以在其中调用 trigger 函数触发响应了:
// 定义一个对象,将自定义的 add 方法定义到该对象下
const mutableInstrumentations = {
add(key) {
// this 仍然指向的是代理对象,通过 raw 属性获取原始数据对象
const target = this.raw
// 通过原始数据对象执行 add 方法添加具体的值,
// 注意,这里不再需要 .bind 了,因为是直接通过 target 调用并执行的
const res = target.add(key)
// 调用 trigger 函数触发响应,并指定操作类型为 ADD
trigger(target, key, 'ADD')
// 返回操作结果
return res
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
自定义的 add 函数内的 this 仍然指向代理对象,所以需要通过 this.raw 获取原始数据对象。
有了原始数据对象后,就可以通过它调用 target.add 方法,这样就不再需要 .bind 绑定了。待添加操作完成后,调用 trigger 函数触发响应。
我们知道,在 trigger 函数的实现中,当操作类型是 ADD 或 DELETE 时,会取出与 ITERATE_KEY 相关联的副作用函数并执行,这样就可以触发通过访问 size 属性所收集的副作用函数来执行了。
function trigger(target, key, type, newVal) {
const depsMap = bucket.get(target)
if (!depsMap) return
const effects = depsMap.get(key)
// 省略无关内容
// 当操作类型 type 为 ADD 时,会取出与 ITERATE_KEY 相关联的副作用函数并执行
if (type === 'ADD' || type === 'DELETE') {
const iterateEffects = depsMap.get(ITERATE_KEY)
iterateEffects && iterateEffects.forEach(effectFn => {
if (effectFn !== activeEffect) {
effectsToRun.add(effectFn)
}
})
}
effectsToRun.forEach(effectFn => {
if (effectFn.options.scheduler) {
effectFn.options.scheduler(effectFn)
} else {
effectFn()
}
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
当然,如果调用 add 方法添加的元素已经存在于 Set 集合中了,就不再需要触发响应了,这样做对性能更加友好,因此,我们可以对代码做如下优化:
const mutableInstrumentations = {
add(key) {
const target = this.raw
// 先判断值是否已经存在
const hadKey = target.has(key)
// 只有在值不存在的情况下,才需要触发响应
const res = target.add(key)
if (!hadKey) {
trigger(target, key, 'ADD')
}
return res
}
}
2
3
4
5
6
7
8
9
10
11
12
13
先调用 target.has 方法判断值是否已经存在,只有在值不存在的情况下才需要触发响应。
在此基础上,我们可以按照类似的思路轻松地实现 delete 方法:
const mutableInstrumentations = {
delete(key) {
const target = this.raw
const hadKey = target.has(key)
const res = target.delete(key)
// 当要删除的元素确实存在时,才触发响应
if (hadKey) {
trigger(target, key, 'DELETE')
}
return res
}
}
2
3
4
5
6
7
8
9
10
11
12
与 add 方法的区别在于,delete 方法只有在要删除的元素确实在集合中存在时,才需要触发响应,这一点恰好与 add 方法相反。
# 避免污染原始数据
Map 数据类型拥有 get 和 set 这两个方法,当调用 get 方法读取数据时,需要调用 track 函数追踪依赖建立响应联系;当调用 set 方法设置数据时,需要调用trigger 方法触发响应。如下面的代码所示:
const p = reactive(new Map([['key', 1]]))
effect(() => {
console.log(p.get('key'))
})
p.set('key', 2) // 触发响应
2
3
4
5
6
7
其实想要实现上面这段代码所展示的功能并不难,因为我们已经有了实现 add、delete 等方法的经验。下面是 get 方法的具体实现:
const mutableInstrumentations = {
get(key) {
// 获取原始对象
const target = this.raw
// 判断读取的 key 是否存在
const had = target.has(key)
// 追踪依赖,建立响应联系
track(target, key)
// 如果存在,则返回结果。这里要注意的是,如果得到的结果 res 仍然是可代理的数据,
// 则要返回使用 reactive 包装后的响应式数据
if (had) {
const res = target.get(key)
return typeof res === 'object' ? reactive(res) : res
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
在非浅响应的情况下,如果得到的数据仍然可以被代理,那么要调用 reactive(res) 将数据转换成响应式数据后返回。在浅响应模式下,就不需要这一步了。
当 set 方法被调用时,需要调用trigger 方法触发响应。只不过在触发响应的时候,需要区分操作的类型是 SET 还是 ADD,如下面的代码所示:
const mutableInstrumentations = {
set(key, value) {
const target = this.raw
const had = target.has(key)
// 获取旧值
const oldValue = target.get(key)
// 设置新值
target.set(key, value)
// 如果不存在,则说明是 ADD 类型的操作,意味着新增
if (!had) {
trigger(target, key, 'ADD')
} else if (oldValue !== value || (oldValue === oldValue && value === value)) {
// 如果存在,并且值变了,则是 SET 类型的操作,意味着修改
trigger(target, key, 'SET')
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
这段代码的关键点在于,我们需要判断设置的 key 是否存在,以便区分不同的操作类型。对于 SET 类型和 ADD 类型的操作来说,它们最终触发的副作用函数是不同的。因为 ADD 类型的操作会对数据的 size 属性产生影响,所以任何依赖 size 属性的副作用函数都需要在 ADD 类型的操作发生时重新执行。
上面给出的 set 函数的实现能够正常工作,但它仍然存在问题,即 set 方法会污染原始数据:
// 原始 Map 对象 m
const m = new Map()
// p1 是 m 的代理对象
const p1 = reactive(m)
// p2 是另外一个代理对象
const p2 = reactive(new Map())
// 为 p1 设置一个键值对,值是代理对象 p2
p1.set('p2', p2)
effect(() => {
// 注意,这里我们通过原始数据 m 访问 p2
console.log(m.get('p2').size)
})
// 注意,这里我们通过原始数据 m 为 p2 设置一个键值对 foo --> 1
m.get('p2').set('foo', 1)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
首先创建了一个原始 Map 对象 m,p1 是对象 m 的代理对象,接着创建另外一个代理对象 p2,并将其作为值设置给 p1,即 p1.set('p2',p2)。
接下来问题出现了:在副作用函数中,我们通过原始数据 m 来读取数据值,然后又通过原始数据 m 设置数据值,此时发现副作用函数重新执行了。意味着原始用户可以操作原始数据,又能够操作响应式数据。
这其实不是我们所期望的行为,因为原始数据不应该具有响应式数据的能力,否则就意味着用户既可以操作原始数据,又能够操作响应式数据,这样一来代码就乱套了。
导致问题的原因是什么呢?
const mutableInstrumentations = {
set(key, value) {
const target = this.raw
const had = target.has(key)
const oldValue = target.get(key)
// 我们把 value 原封不动地设置到原始数据上
target.set(key, value)
if (!had) {
trigger(target, key, 'ADD')
} else if (oldValue !== value || (oldValue === oldValue && value === value)) {
trigger(target, key, 'SET')
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
在 set 方法内,我们把 value 原样设置到了原始数据 target 上。如果 value 是响应式数据,就意味着设置到原始对象上的也是响应式数据,我们把响应式数据设置到原始数据上的行为称为数据污染。问题:原始数据调用仍会触发响应式
要解决数据污染也不难,只需要在调用 target.set 函数设置值之前对值进行检查即可:只要发现即将要设置的值是响应式数据,那么就通过 raw 属性获取原始数据,再把原始数据设置到 target 上
const mutableInstrumentations = {
set(key, value) {
const target = this.raw
const had = target.has(key)
const oldValue = target.get(key)
// 获取原始数据,由于 value 本身可能已经是原始数据,所以此时 value.raw 不存在,则直接使用 value
const rawValue = value.raw || value
target.set(key, rawValue)
if (!had) {
trigger(target, key, 'ADD')
} else if (oldValue !== value || (oldValue === oldValue && value === value)) {
trigger(target, key, 'SET')
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
现在的实现已经不会造成数据污染了。凡事有了新的问题,我们一直使用 raw 属性来访问原始数据是有缺陷的,因为它可能与用户自定义的 raw 属性冲突,所以在一个严谨的实现中,我们需要使用唯一的标识来作为访问原始数据的键,例如使用 Symbol 类型来代替。
其实除了 set 方法需要避免污染原始数据之外,Set 类型的 add 方法、普通对象的写值操作,还有为数组添加元素的方法等,都需要做类似的处理。
# 处理 forEach
集合类型的 forEach 方法类似于数组的 forEach 方法,我们先来看看它是如何工作的:
const m = new Map([
[{ key: 1 }, { value: 1 }]
])
effect(() => {
m.forEach(function (value, key, m) {
console.log(value) // { value: 1 }
console.log(key) // { key: 1 }
})
})
2
3
4
5
6
7
8
9
10
forEach 方法接收一个回调函数作为参数,该回调函数会在 Map 的每个键值对上被调用。回调函数接收三个参数,分别是值、键以及原始 Map 对象。
遍历操作只与键值对的数量有关,因此任何会修改 Map 对象键值对数量的操作都应该触发副作用函数重新执行,例如 delete 和 add 方法等。所以当 forEach 函数被调用时,我们应该让副作用函数与 ITERATE_KEY 建立响应联系:
const mutableInstrumentations = {
forEach(callback) {
// 取得原始数据对象
const target = this.raw
// 与 ITERATE_KEY 建立响应联系
track(target, ITERATE_KEY)
// 通过原始数据对象调用 forEach 方法,并把 callback 传递过去
target.forEach(callback)
}
}
2
3
4
5
6
7
8
9
10
这样我们就实现了对 forEach 操作的追踪,使用下面的代码进行测试,可以发现,能够按照预期工作:
const p = reactive(new Map([
[{ key: 1 }, { value: 1 }]
]))
effect(() => {
p.forEach(function (value, key) {
console.log(value) // { value: 1 }
console.log(key) // { key: 1 }
})
})
// 能够触发响应
p.set({ key: 2 }, { value: 2 })
2
3
4
5
6
7
8
9
10
11
12
13
然而,上面给出的 forEach 函数仍然存在缺陷,我们在自定义实现的 forEach 方法内,通过原始数据对象调用了原生的forEach 方法,即
// 通过原始数据对象调用 forEach 方法,并把 callback 传递过去
target.forEach(callback)
2
这意味着,传递给 callback 回调函数的参数将是非响应式数据。这导致下面的代码不能按预期工作:
const key = { key: 1 }
const value = new Set([1, 2, 3])
const p = reactive(new Map([
[key, value]
]))
effect(() => {
p.forEach(function (value, key) {
console.log(value.size) // 3
})
})
p.get(key).delete(1)
2
3
4
5
6
7
8
9
10
11
12
13
我们在副作用函数中使用 forEach 方法遍历 p,并在回调函数中访问 value.size。最后,我们尝试删除 Set 类型数据中值为 1 的元素,却发现没能触发副作用函数重新执行。导致问题的原因就是上面曾提到的,当通过 value.size 访问 size 属性时,这里的 value 是原始数据对象,即 new Set([1, 2, 3]),而非响应式数据对象,因此无法建立响应联 系。但这其实不符合直觉,因为 reactive 本身是深响应,forEach 方法的回调函数所接收到的参数也应该是响应式数据才对。
为了解决这个问题,我们需要对现有实现做一些修改,如下面的代码所示:
const mutableInstrumentations = {
forEach(callback) {
// wrap 函数用来把可代理的值转换为响应式数据
const wrap = (val) => typeof val === 'object' ? reactive(val) : val
const target = this.raw
track(target, ITERATE_KEY)
// 通过 target 调用原始 forEach 方法进行遍历
target.forEach((v, k) => {
// 手动调用 callback,用 wrap 函数包裹 value 和 key 后再传给 callback,这样就实现了深响应
callback(wrap(v), wrap(k), this)
})
}
}
2
3
4
5
6
7
8
9
10
11
12
13
既然 callback 函数的参数不是响应式的,那就将它转换成响应式的。所以在上面的代码中,我们又对 callback 函数的参数做了一层包装,即把传递给 callback 函数的参数包装成响应式的。此时,如果再次尝试运行前文给出的例子,会发现它能够按预期工作了。
forEach 的底层逻辑和 get 是相似的,都是在读的过程中转为 reactive。
forEach 函数除了接收 callback 作为参数外,它还接收第二个参数 thisArg,该参数可以用来指定 callback 函数执行时的 this 值。更加完善的实现如下所示:
const mutableInstrumentations = {
// 接收第二个参数
forEach(callback, thisArg) {
const wrap = (val) => typeof val === 'object' ? reactive(val) : val
const target = this.raw
track(target, ITERATE_KEY)
target.forEach((v, k) => {
// 通过 .call 调用 callback,并传递 thisArg
callback.call(thisArg, wrap(v), wrap(k), this)
})
}
}
2
3
4
5
6
7
8
9
10
11
12
13
至此,我们的工作仍然没有完成。无论是使用 for...in 循环遍历一个对象,还是使用 forEach 循环遍历一个集合,它们的响应联系都是建立在 ITERATE_KEY 与副作用函数之间的。然而,使用 for...in 来遍历对象与使用forEach 遍历集合之间存在本质的不同。当使用 for...in 循环遍历对象时,它只关心对象的键,而不关心对象的值,如以下代码所示:
effect(() => {
for (const key in obj) {
console.log(key)
}
})
2
3
4
5
只有当新增、删除对象的 key 时,才需要重新执行副作用函数。所以我们在trigger 函数内判断操作类型是否是 ADD 或 DELETE,进而知道是否需要触发那些与 ITERATE_KEY 相关联的副作用函数重新执行。
对于 SET 类型的操作来说,因为它不会改变一个对象的键的数量,所以当 SET 类型的操作发生时,不需要触发副作用函数重新执行。但这个规则不适用于 Map 类型的 forEach 遍历,当使用 forEach 遍历 Map 类型的数据时,它既关心键,又关心值:
const p = reactive(new Map([
['key', 1]
]))
effect(() => {
p.forEach(function (value, key) {
// forEach 循环不仅关心集合的键,还关心集合的值
console.log(value) // 1
})
})
p.set('key', 2) // 即使操作类型是 SET,也应该触发响应
2
3
4
5
6
7
8
9
10
11
12
当调用 p.set('key', 2) 修改值的时候,也应该触发副作用函数重新执行,即使它的操作类型是 SET。
因此,我们应该修改 trigger 函数的代码来弥补这个缺陷:
function trigger(target, key, type, newVal) {
console.log('trigger', key)
const depsMap = bucket.get(target)
if (!depsMap) return
const effects = depsMap.get(key)
const effectsToRun = new Set()
effects && effects.forEach(effectFn => {
if (effectFn !== activeEffect) {
effectsToRun.add(effectFn)
}
})
if (
type === 'ADD' ||
type === 'DELETE' ||
// 如果操作类型是 SET,并且目标对象是 Map 类型的数据,
// 也应该触发那些与 ITERATE_KEY 相关联的副作用函数重新执行
(
type === 'SET' &&
Object.prototype.toString.call(target) === '[object Map]'
)
) {
const iterateEffects = depsMap.get(ITERATE_KEY)
iterateEffects && iterateEffects.forEach(effectFn => {
if (effectFn !== activeEffect) {
effectsToRun.add(effectFn)
}
})
}
// 省略部分内容
effectsToRun.forEach(effectFn => {
if (effectFn.options.scheduler) {
effectFn.options.scheduler(effectFn)
} else {
effectFn()
}
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
增加了一个判断条件:如果操作的目标对象是 Map 类型的,则 SET 类型的操作也应该触发那些与 ITERATE_KEY 相关联的副作用函数重新执行。
# 迭代器方法
集合类型有三个迭代器方法:
- entries
- keys
- values
调用这些方法会得到相应的迭代器,并且可以使用 for...of 进行循环迭代,例如:
const m = new Map([
['key1', 'value1'],
['key2', 'value2']
])
for (const [key, value] of m.entries()) {
console.log(key, value)
}
// 输出:
// key1 value1
// key2 value2
2
3
4
5
6
7
8
9
10
11
另外,由于 Map 或 Set 类型本身部署了 Symbol.iterator 方法,因此它们可以使用 for...of 进行迭代:
for (const [key, value] of m {
console.log(key, value)
}
// 输出:
// key1 value1
// key2 value2
2
3
4
5
6
for...of 就是一个语法糖,会自动消费迭代器的 next 方法
当然,我们也可以调用迭代器函数取得迭代器对象后,手动调用迭代器对象的next 方法获取对应的值:
const itr = m[Symbol.iterator]()
console.log(itr.next()) // { value: ['key1', 'value1'], done: false }
console.log(itr.next()) // { value: ['key2', 'value2'], done: false }
console.log(itr.next()) // { value: undefined, done: true }
2
3
4
实际上,m[Symbol.iterator] 与 m.entries 是等价的:
console.log(m[Symbol.iterator] === m.entries) // true
这就是为什么上例中使用 for...of 循环迭代 m.entries 和 m 会得到同样的结果。
理解了这些内容后,我们就可以尝试实现对迭代器方法的代理了。不过在这之前,不妨做一些尝试,看看会发生什么:
const p = reactive(new Map([
['key1', 'value1'],
['key2', 'value2']
]))
effect(() => {
// TypeError: p is not iterable
for (const [key, value] of p) {
console.log(key, value)
}
})
p.set('key3', 'value3')
2
3
4
5
6
7
8
9
10
11
12
13
首先创建一个代理对象 p,接着尝试使用 for...of 循环遍历它,却得到了一个错误:“p 是不可迭代的”。如果一个对象正确地实现了 Symbol.iterator 方法,那么它就是可迭代的。很显然,代理对象 p 没有实现 Symbol.iterator 方法,因此我们得到了上面的错误。
但实际上,当我们使用 for...of 循环迭代一个代理对象时,内部会试图从代理对象p 上读取 p[Symbol.iterator] 属性,这个操作会触发 get 拦截函数,所以我们仍然可以把 Symbol.iterator 方法的实现放到 mutableInstrumentations 中:
const mutableInstrumentations = {
[Symbol.iterator]() {
// 获取原始数据对象 target
const target = this.raw
// 获取原始迭代器方法
const itr = target[Symbol.iterator]()
// 将其返回
return itr
}
}
2
3
4
5
6
7
8
9
10
实现很简单,不过是把原始的迭代器对象返回而已,这样就能够使用 for...of 循环迭代代理对象 p 了,然而事情不可能这么简单。
在学习 forEach 方法时提到过,传递给 callback 的参数是包装后的响应式数据:
p.forEach((value, key) => {
// value 和 key 如果可以被代理,那么它们就是代理对象,即响应式数据
})
2
3
同理,使用 for...of 循环迭代集合时,如果迭代产生的值也是可以被代理的,那么也应该将其包装成响应式数据,例如:
for (const [key, value] of p) {
// 期望 key 和 value 是响应式数据
}
2
3
因此,我们需要修改代码:
const mutableInstrumentations = {
[Symbol.iterator]() {
// 获取原始数据对象 target
const target = this.raw
// 获取原始迭代器方法
const itr = target[Symbol.iterator]()
const wrap = (val) => typeof val === 'object' && val !== null ? reactive(val) : val
// 返回自定义的迭代器
return {
next() {
// 调用原始迭代器的 next 方法获取 value 和 done
const { value, done } = itr.next()
return {
// 如果 value 不是 undefined,则对其进行包裹
value: value ? [wrap(value[0]), wrap(value[1])] : value,
done
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
为了实现对 key 和 value 的包装,我们需要自定义实现的迭代器,在其中调用原始迭代器获取值 value 以及代表是否结束的 done。如果值value 不为 undefined,则对其进行包装,最后返回包装后的代理对象,这样当使用 for...of 循环进行迭代时,得到的值就会是响应式数据了。
最后,为了追踪 for...of 对数据的迭代操作,我们还需要调用 track 函数,让副作用函数与 ITERATE_KEY 建立联系:
const mutableInstrumentations = {
[Symbol.iterator]() {
const target = this.raw
const itr = target[Symbol.iterator]()
const wrap = (val) => typeof val === 'object' && val !== null ? reactive(val) : val
// 调用 track 函数建立响应联系
track(target, ITERATE_KEY)
return {
next() {
const { value, done } = itr.next()
return {
value: value ? [wrap(value[0]), wrap(value[1])] : value,
done
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
由于迭代操作与集合中元素的数量有关,所以只要集合的 size 发生变化,就应该触发迭代操作重新执行。因此,我们在调用 track 函数时让 ITERATE_KEY 与副作用函数建立联系。
完成这一步后,集合的响应式数据功能就相对完整了,我们可以测试一下:
const p = reactive(new Map([
['key1', 'value1'],
['key2', 'value2']
]))
effect(() => {
for (const [key, value] of p) {
console.log(key, value)
}
})
p.set('key3', 'value3') // 能够触发响应
2
3
4
5
6
7
8
9
10
11
12
前面我们说过,由于 p.entries 与 p[Symbol.iterator] 等价,所以我们可以使用同样的代码来实现对 p.entries 函数的拦截:
const mutableInstrumentations = {
// 共用 iterationMethod 方法
[Symbol.iterator]: iterationMethod,
entries: iterationMethod
}
// 抽离为独立的函数,便于复用
function iterationMethod() {
const target = this.raw
const itr = target[Symbol.iterator]()
const wrap = (val) => typeof val === 'object' ? reactive(val) : val
track(target, ITERATE_KEY)
return {
next() {
const { value, done } = itr.next()
return {
value: value ? [wrap(value[0]), wrap(value[1])] : value,
done
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
但当尝试运行代码使用 for...of 进行迭代时,会得到一个错误:
// TypeError: p.entries is not a function or its return value is not iterable
for (const [key, value] of p.entries()) {
console.log(key, value)
}
2
3
4
错误的大意是 p.entries 的返回值不是一个可迭代对象。很显然,p.entries 函数的返回值是一个对象,该对象带有 next 方法,但不具有 Symbol.iterator 方法,因此它确实不是一个可迭代对象。这里是经常出错的地方,切勿把可迭代协议和迭代器协议搞混。
可迭代协议指的是一个对象实现了 Symbol.iterator 方法,而迭代器协议指的是一个对象实现了 next 方法。但一个对象可以同时实现可迭代协议和迭代器协议,例如:
const obj = {
// 迭代器协议
next() {
// ...
},
// 可迭代协议
[Symbol.iterator]() {
return this
}
}
2
3
4
5
6
7
8
9
10
所以解决问题的方法也自然而然地出现了:
// 抽离为独立的函数,便于复用
function iterationMethod() {
const target = this.raw
const itr = target[Symbol.iterator]()
const wrap = (val) => typeof val === 'object' ? reactive(val) : val
track(target, ITERATE_KEY)
return {
next() {
const { value, done } = itr.next()
return {
value: value ? [wrap(value[0]), wrap(value[1])] : value,
done
}
}
// 实现可迭代协议
[Symbol.iterator]() {
return this
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
现在一切都能正常工作了。
# values 与 keys 方法
values 方法的实现与 entries 方法类似,不同的是,当使用 for...of 迭代 values 时,得到的仅仅是 Map 数据的值,而非键值对:
for (const value of p.values()) {
console.log(value)
}
const mutableInstrumentations = {
// 共用 iterationMethod 方法
[Symbol.iterator]: iterationMethod,
entries: iterationMethod,
values: valuesIterationMethod
}
function valuesIterationMethod() {
// 获取原始数据对象 target
const target = this.raw
// 通过 target.values 获取原始迭代器方法
const itr = target.values()
const wrap = (val) => typeof val === 'object' ? reactive(val) : val
track(target, ITERATE_KEY)
// 将其返回
return {
next() {
const { value, done } = itr.next()
return {
// value 是值,而非键值对,所以只需要包裹 value 即可
value: wrap(value),
done
}
},
[Symbol.iterator]() {
return this
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
其中,valuesIterationMethod 与 iterationMethod 这两个方法有两点区别:
iterationMethod 通过 target[Symbol.iterator] 获取迭代器对象,而valuesIterationMethod 通过 target.values 获取迭代器对象;
iterationMethod 处理的是键值对,即 [wrap(value[0]), wrap(value[1])],而valuesIterationMethod 只处理值,即 wrap(value)。
由于它们的大部分逻辑相同,所以我们可以将它们封装到一个可复用的函数中。但为了便于理解,这里仍然将它们设计为两个独立的函数来实现。
keys 方法与 values 方法非常类似,不同点在于,前者处理的是键而非值。因此,我们只需要修改 valuesIterationMethod 方法中的一行代码,即可实现对 keys方法的代理。
const itr = target.values() // 删除
// 把上面这句代码替换成下面:
const itr = target.keys() // 新增
2
3
这么做的确能够达到目的,但如果我们尝试运行如下测试用例,就会发现存在缺陷:
const p = reactive(new Map([
['key1', 'value1'],
['key2', 'value2']
]))
effect(() => {
for (const value of p.keys()) {
console.log(value) // key1 key2
}
})
p.set('key2', 'value3') // 这是一个 SET 类型的操作,它修改了 key2 的值
2
3
4
5
6
7
8
9
10
11
12
使用 for...of 循环来遍历 p.keys,然后调用 p.set('key2','value3') 修改键为 key2 的值。在这个过程中,Map 类型数据的所有键都没有发生变化,仍然是 key1 和 key2,所以在理想情况下,副作用函数不应该执行。但如果你尝试运行上例,会发现副作用函数仍然重新执行了。
这是因为,我们对 Map 类型的数据进行了特殊处理。前文提到,即使操作类型为 SET,也会触发那些与 ITERATE_KEY 相关联的副作用函数重新执行,trigger 函数的代码可以证明这一点:
function trigger(target, key, type, newVal) {
// 省略其他代码
if (
type === 'ADD' ||
type === 'DELETE' ||
// 即使是 SET 类型的操作,也会触发那些与 ITERATE_KEY 相关联的副作用函数重新执行
(
type === 'SET' &&
Object.prototype.toString.call(target) === '[object Map]'
)
) {
const iterateEffects = depsMap.get(ITERATE_KEY)
iterateEffects && iterateEffects.forEach(effectFn => {
if (effectFn !== activeEffect) {
effectsToRun.add(effectFn)
}
})
}
// 省略其他代码
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
这对于 values 或 entries 等方法来说是必需的,但对于 keys 方法来说则没有必要,因为 keys 方法只关心 Map 类型数据的键的变化,而不关心值的变化。
解决办法以下代码所示:
const MAP_KEY_ITERATE_KEY = Symbol()
function keysIterationMethod() {
// 获取原始数据对象 target
const target = this.raw
// 获取原始迭代器方法
const itr = target.keys()
const wrap = (val) => typeof val === 'object' ? reactive(val) : val
// 调用 track 函数追踪依赖,在副作用函数与 MAP_KEY_ITERATE_KEY 之间建立响应联系
track(target, MAP_KEY_ITERATE_KEY)
// 将其返回
return {
next() {
const { value, done } = itr.next()
return {
value: wrap(value),
done
}
},
[Symbol.iterator]() {
return this
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
当调用 track 函数追踪依赖时,我们使用MAP_KEY_ITERATE_KEY 代替了 ITERATE_KEY。其中 MAP_KEY_ITERATE_KEY与 ITERATE_KEY 类似,是一个新的 Symbol 类型,用来作为抽象的键。这样就实现了依赖收集的分离,即 values 和 entries 等方法仍然依赖 ITERATE_KEY,而 keys 方法则依赖 MAP_KEY_ITERATE_KEY。
当 SET 类型的操作只会触发与 ITERATE_KEY 相关联的副作用函数重新执行时,自然就会忽略那些与 MAP_KEY_ITERATE_KEY 相关联的副作用函数。
但当 ADD 和 DELETE 类型的操作发生时,除了触发与 ITERATE_KEY 相关联的副作用函数重新执行之外,还需要触发与 MAP_KEY_ITERATE_KEY 相关联的副作用函数重新执行,因此我们需要修改 trigger 函数的代码,如下所示:
function trigger(target, key, type, newVal) {
// 省略其他代码
if (
// 操作类型为 ADD 或 DELETE
(type === 'ADD' || type === 'DELETE') &&
// 并且是 Map 类型的数据
Object.prototype.toString.call(target) === '[object Map]'
) {
// 则取出那些与 MAP_KEY_ITERATE_KEY 相关联的副作用函数并执行
const iterateEffects = depsMap.get(MAP_KEY_ITERATE_KEY)
iterateEffects && iterateEffects.forEach(effectFn => {
if (effectFn !== activeEffect) {
effectsToRun.add(effectFn)
}
})
}
// 省略其他代码
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
这样,就能够避免不必要的更新了:
const p = reactive(new Map([
['key1', 'value1'],
['key2', 'value2']
]))
effect(() => {
for (const value of p.keys()) {
console.log(value)
}
})
p.set('key2', 'value3') // 不会触发响应
p.set('key3', 'value3') // 能够触发响应
2
3
4
5
6
7
8
9
10
11
12
13
# 总结
- Vue.js 3 的响应式数据是基于Proxy 实现的,Proxy 可以为其他对象创建一个代理对象。所谓代理,指的是对一个对象基本语义的代理。它允许我们拦截并重新定义对一个对象的基本操作。使用 Reflect.* 方法并指定正确的 receiver 来解决访问器属性的 this 指向问题。
- 在ECMAScript 规范中,JavaScript 中有两种对象,其中一种叫作常规对象,另一种叫作异质对象。一个对象是函数还是其他对象,是由部署在该对象上的内部方法和内部槽决定的。
- 代理对象的本质,就是查阅规范并找到可拦截的基本操作的方法。有一些操作并不是基本操作,而是复合操作,这需要我们查阅规范了解它们都依赖哪些基本操作,从而通过基本操作的拦截方法间接地处理复合操作。
- 添加和删除属性都会影响 for...in 循环的执行次数,所以当这些操作发生时,需要触发与 ITERATE_KEY 相关联的副作用函数重新执行。而修改属性值则不影响for...in 循环的执行次数,因此无须处理。
- 想要基于 Proxy 实现一个相对完善的响应系统,免不了去了解 ECMAScript 规范。
- 为了实现深响应(或只读),我们需要在返回属性值之前,对值做一层包装,将其包装为响应式(或只读)数据后再返回。
- 数组是一个异质对象,因为数组对象部署的内部方法 [[DefineOwnProperty]] 不同于常规对象。通过索引为数组设置新的元素,可能会隐式地改变数组 length 属性的值。对应地,修改数组 length 属性的值,也可能会间接影响数组中的已有元素。所以在触发响应的时候需要额外注意。
- 使用 for...in 循环遍历数组与遍历普通对象区别不大,唯一需要注意的是,当追踪 for...in 操作时,应该使用数组的 length 作为追踪的 key。for...of 基于迭代协议工作,数组内建了Symbol.iterator 方法。数组迭代器执行时,会读取数组的 length 属性或数组的索引。因此,我们不需要做其他额外的处理,就能够实现对 for...of 迭代的响应式支持。
- 对于数组元素的查找,需要注意的一点是,用户既可能使用代理对象进行查找,也可能使用原始对象进行查找。为了支持这两种形式,我们需要重写数组的查找方法。当用户使用这些方法查找元素时,我们可以先去代理对象中查找,如果找不到,再去原始数组中查找。
- 会隐式修改数组长度的原型方法,即 push、pop、shift、unshift以及 splice 等方法。调用这些方法会间接地读取和设置数组的 length 属性,因此,在不同的副作用函数内对同一个数组执行上述方法,会导致多个副作用函数之间循环调用,最终导致调用栈溢出。为了解决这个问题,我们使用一个标记变量shouldTrack 来代表是否允许进行追踪,然后重写了上述这些方法,目的是,当这些方法间接读取 length 属性值时,我们会先将 shouldTrack 的值设置为 false,即禁止追踪。这样就可以断开 length 属性与副作用函数之间的响应联系,从而避免循环调用导致的调用栈溢出。
- 集合类型指 Set、Map、WeakSet 以及 WeakMap。
- 集合类型不同于普通对象,它有特定的数据操作方法。当使用 Proxy代理集合类型的数据时要格外注意,例如,集合类型的 size 属性是一个访问器属性,当通过代理对象访问 size 属性时,由于代理对象本身并没有部署 [[SetData]] 这样的内部槽,所以会发生错误。
- 通过代理对象执行集合类型的操作方法时,要注意这些方法执行时的 this 指向,我们需要在 get 拦截函数内通过 .bind函数为这些方法绑定正确的 this 值。
- 集合类型响应式数据的实现:我们需要通过“重写”集合方法的方式来实现自定义的能力,当 Set 集合的 add方法执行时,需要调用 trigger 函数触发响应。我们也讨论了关于“数据污染”的问题。
- 数据污染指的是不小心将响应式数据添加到原始数据中,它导致用户可以通过原始数据执行响应式相关操作,这不是我们所期望的。为了避免这类问题发生,我们通过响应式数据对象的 raw 属性来访问对应的原始数据对象,后续操作使用原始数据对象就可以了。
- 集合类型的遍历,即 forEach 方法。集合的 forEach 方法与对象的 for...in 遍历类似,最大的不同体现在,当使用for...in 遍历对象时,我们只关心对象的键是否变化,而不关心值;但使用forEach 遍历集合时,我们既关心键的变化,也关心值的变化。